Contents
概述
k8s 中的日志处理分为三类:
- 容器内日志: 即用户的业务日志,如打在了容器内的特定目录下,一般采用 sidecar 方式收集
- 容器标准输出: 容器的 stdout和 stderr 日志,即标准输出
- 日志转 metric: 将日志信息提取为监控指标,如提取 nginx 日志为 qps、请求延迟等指标,也属于监控范畴
容器内日志
和主机采集(daemonset)方式相比,容器内日志的采集方案一般使用 sidecar,好处是:
- 和容器本身的生命周期一致,容器销毁 sidecar 也不再采集,不需要对 sidecar 做回收或管理
- 更方便的做资源规划和计费,日志采集一般会消耗很多的 cpu 和带宽资源,将 sidecar 容器和业务容器绑定在一个 pod 中,可以更方便地做 quota 管理、资源计费。
- sidecar 和业务容器使用 emptydir 共享日志目录,多租户环境下更加安全。
- sidecar 可以动态感知容器的环境信息,如 pod ip,节点名称等,比 daemonset 或者主机采集方便很多。
- 如果容器内也需要暴露 metric,即日志转 metric,使用sidecar 方式也更加方便,sidecar 暴露 prometheus 的 metric 即可。
示例如下:
apiVersion: v1
kind: Pod
metadata:
labels:
app: demo
name: demo
namespace: demo
spec:
containers:
- image: hub.baidubce.com/cce/nginx-alpine-go-test:latest
name: container01
resources:
limits:
cpu: "4"
memory: "8589934592"
requests:
cpu: "4"
memory: "8589934592"
volumeMounts:
- mountPath: /temp
name: logtest-var-applog
image: hub.baidubce.com/cce/fluent-bit:0.3.2
name: fluent
resources:
limits:
cpu: 50m
memory: 128Mi
requests:
cpu: 5m
memory: 40Mi
volumeMounts:
- mountPath: /var/applog
name: logtest-var-applog
- mountPath: /fluent-bit/etc/
name: log-config-volume
readOnly: true
volumes:
- emptyDir: {}
name: logtest-var-applog
- configMap:
defaultMode: 420
name: log-config-s-bu9gniek
name: log-config-volume
fluent-bit 就是 sidecar 容器,和主容器(业务容器)以emptyDir的方式共享了日志目录,并在 sidecar 中执行采集。
log-config的 configmap 就是用户配置的日志采集规则,即采集什么、推送到哪里(可以自定义自己的 es 地址),configmap 的配置会映射为fluent-bit的配置文件
apiVersion: v1
kind: ConfigMap
metadata:
name: log-config-{{ serviceId }}
labels:
app: fluent-bit
data:
fluent-bit.conf: |
[SERVICE]
Flush 1
Log_Level info
Daemon off
HTTP_Server On
HTTP_Listen 0.0.0.0
HTTP_Port 2020
@INCLUDE input-kubernetes.conf
@INCLUDE filter-kubernetes.conf
@INCLUDE output-fluntd.conf
input-kubernetes.conf: |
[INPUT]
Name tail
Tag applog.*
Path /var/applog/*.log
Exclude_Path /var/applog/4.log
Path_Key filename
DB /var/applog/flb_app.db
Mem_Buf_Limit 5MB
Skip_Long_Lines On
Refresh_Interval 10
filter-kubernetes.conf: |
[FILTER]
Name modify
Match *
Add _node_name ${NODE_NAME}
Add _node_ip ${NODE_IP}
Add _pod_name ${POD_NAME}
Add _pod_namespace ${POD_NAMESPACE}
Add _pod_ip ${POD_IP}
Add pod_uid ${POD_UID}
output-fluntd.conf: |
[OUTPUT]
Name es
Match *
Host {{ esHost }}
Port {{ esPort }}
Index {{ esIndex }}
HTTP_User {{ esUserName }}
HTTP_Passwd {{ esUserPassword }}
日志转 metric
日志转 metric 也是采用 sidecar 方案,只是多挂了一个 sidecar运行 grok 进程,grok 是一个开源组件,负责将日志内容根据特定规则转化为 prometheus 的 metric。
也可以将 grok 和 fluent-bit 合二为一,作为一个 sidecar进程,维护更加方便。
以 nginx 日志为例,采集 nginx的三种指标:
- 请求速率:如 1m 周期,每秒的请求数。这里可以展示总请求,也可以按resource请求路径分,或者按verb方法类型分
- 请求错误数:如 1m 周期,请求的 5xx 总数
- 请求耗时:如 5m周期,请求的平均响应时间,可以按请求路径分
nginx 的配置:
log_format main '$remote_addr - $remote_user [$time_local] "$request" '
'$status $body_bytes_sent $request_time "$http_referer" '
'"$http_user_agent" "$http_x_forwarded_for"';
比默认安装的 nginx 多加了一个$request_time,用于分析请求时间
日志内容示例:
180.169.253.135 - - [31/Dec/2019:14:00:01 +0800] "GET /smretpppppppppppppppp HTTP/1.1" 404 3650 0.000"-" "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12032130_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3945.88 Safari/537.36" "-"
grok的配置示例如下:
apiVersion: v1
kind: ConfigMap
metadata:
name: metrics-config-configmap
labels:
app: metrics-exporter
data:
config.yml: |
global:
config_version: 2
input:
type: file
path: /var/applog/*.log
position_file: /var/log/grok_position.db
readall: false
fail_on_missing_logfile: false
position_sync_interval: 1s
max_line_size: 10240
grok:
patterns_dir: /grok/patterns
additional_patterns:
- 'NGUSERNAME [a-zA-Z\.\@\-\+_%]+'
- 'NGUSER %{NGUSERNAME}'
metrics:
- type: counter
name: nginx_request_count
help: Total number of request.
match: '%{IPORHOST:clientip} %{NGUSER:ident} %{NGUSER:auth} \[%{HTTPDATE:timestamp}\] "(?:%{WORD:verb} %{URIPATHPARAM:request}(?: HTTP/%{NUMBER:httpversion})?|%{DATA:rawrequest})" %{NUMBER:response_code} (?:%{NUMBER:bytes}|-) %{NUMBER:request_time}'
labels:
status: '{{.response_code}}'
method: '{{.verb}}'
path: '{{.request}}'
#retention: 10m
- type: histogram
name: nginx_response_time_second
help: nginx_response_time_second histogram
match: '%{IPORHOST:clientip} %{NGUSER:ident} %{NGUSER:auth} \[%{HTTPDATE:timestamp}\] "(?:%{WORD:verb} %{URIPATHPARAM:request}(?: HTTP/%{NUMBER:httpversion})?|%{DATA:rawrequest})" %{NUMBER:response_code} (?:%{NUMBER:bytes}|-) %{NUMBER:request_time}'
value: '{{.request_time}}'
buckets: [0.005, 0.01, 0.025, 0.05, 0.1, 0.25, 0.5, 1, 2.5, 5, 10]
labels:
status: '{{.response_code}}'
method: '{{.verb}}'
path: '{{.request}}'
#retention: 10m
server:
protocol: http
host: 0.0.0.0
port: 9144
path: /metrics
得到的指标为:
nginx_request_count{code="200",method="PUT",path="/api/test",namespace=""...} counter类型
nginx_response_time_second{code="200",method="PUT",path="/api/test",namespace=""...} histogram类型
histogram的bucket设置为:[0.005, 0.01, 0.025, 0.05, 0.1, 0.25, 0.5, 1, 2.5, 5, 10]
备住:若使用summary 方式,计算请求延迟:99%区间的响应时间
- 1.平均延迟:avg(nginx_response_time_second{cluster=””,namespace=””,quantile=”0.99”})
- 2.按状态码分:avg(nginx_response_time_second{cluster=””,namespace=””,quantile=”0.99”}) by (status)
- 3.按方法分:avg(nginx_response_time_second{cluster=””,namespace=””,quantile=”0.99”}) by (method)
- 4.按path 分:avg(nginx_response_time_second{cluster=””,namespace=””,quantile=”0.99”}) by (path)
nginx 日志的分析也可以采用nginx-vts-exporter的开源方案
- nginx-module-vts: nginx的监控模块,能够提供json、html、prometheus格式的数据产出。
- nginx-vts-exporter: 主要用于收集nginx的监控数据,并给Prometheus提供监控接口,默认端口号9913。
需要在编译安装 nginx 时,增加 vts 模块,并部署nginx-vts-exporter
参考:https://www.cnblogs.com/huandada/p/10472031.html
grok 是通用的日志转 metric 方案,上面的 nginx 日志只是一个示范,你可以配置任何的 grok表达式来提取你需要的日志,并转换为 4 种 prometheus 的指标类型。
容器标准输出
容器标准输出的日志默认路径是/var/lib/docker/containers/xxx, kubelet 会将改日志软链到/var/log/pods,同时还有一份/var/log/containers 是对/var/log/pods的软链。不过不同的 K8S 版本,日志的目录格式有所变化,采集时根据版本做区分:
- 1.15 及以下:/var/log/pods/{pod_uid}/
- 1.15 以上:var/log/pods/{pod_name+namespace+rs+uuid}/
因为标准输出的日志由 runtime 写在了机器目录上,因此一般情况下标准输出的采集会在主机上做,即使用 daemonset或者主机进程来部署采集端,这和传统的非容器的 EFK 方案没什么区别,因此就不介绍了。
容器标准输出也可以放在 sidecar 来做,如:将/var/log/pods/{pod_uid}/目录通过 hostpath 挂载到 sidecar 中,在 sidecar 中采集标准输出并推送出去,sidecar 的优点上边已经描述过,因此这也是一种可选方案。
但是在某些场景下sidecar 的方案会出现问题,如 kata容器。我们看下 sidecar 采集的原理:
- 容器标准输出是体现在物理机的/var/log/pods 目录下,由 kata 容器将 stdout 从 kata 虚机中暴露,然后通过 cri 标准实现,打在了物理机的/var/log/目录下。
- 物理机的/var/log/通过 hostpath 挂载到 sidecar 中,fluent-bit 等通过 file watch (fsnotify)观察日志文件的变化,有新日志就推送到 ES
但 kata 容器使用了 virtio-9p 的 fs,9p 是 network filesystem,不支持fsnotify(和nfs一样),因此当 kata 容器使用 9p的方式共享了物理机文件(hostpath)时,kata 容器内无法感知到物理机文件的变化,即sidecar 中的fluent-bit无法识别到新日志变更,即无法推送日志。
普通 docker 启动的是 runc 容器,hostpath 挂载到容器内的文件和原始的物理机文件就是同一份文件,只是引用不同,不是网络挂载,因此不存在该问题。
解决方式:
- 改造fluent-bit代码,将 fsnotify 机制改为 poll 轮询机制,就没有这个问题了,不过日志采集用 poll 方式性能太差,fluentd、fluent-bit、filebeat 默认都不会用这种方式。
- 放弃 sidecar方案,改为物理机上直接采集日志,不过需要考虑租户隔离,配置重启的问题,实现可能比较麻烦。
最终实现方案:
伪 sidecar 模式,每台机器上运行一个 control-agent,为这台机器上每一个需要采日志的用户pod都搭配一个日志采集容器(runc启动),并负责回收这些采集容器、同步 configmap
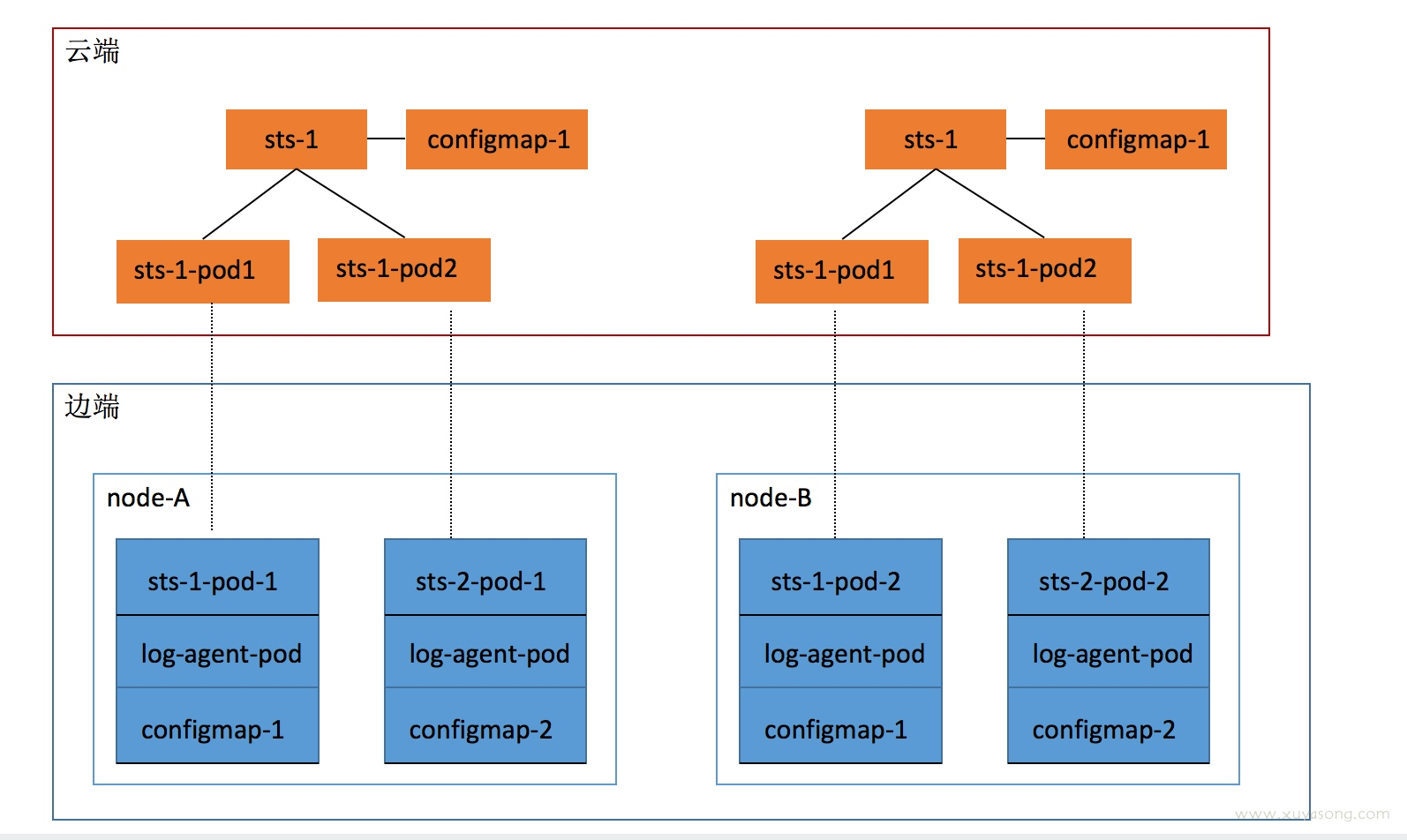
流程如下:
- 为每台机器运行一个 log-agent(daemonset 部署),负责管理每个 pod 的 fluent-bit 的agent 管理
- 每分钟同步一次,如果有新 pod在这台机器产生,且该 pod 符合条件(3 个筛选),就开始该 pod 的同步逻辑
- 同步pod:在 monitor 的 ns 下创建一个 log-{pod_name}-{pod_uid}的 pod,里面运行了 fluent-bit(lama),使用了 名为log-{pod_name}-{pod_uid}的configmap
- 同步 configmap:同步pod 时,获取 pod 关联的 origin configmap,然后新建一个configmap,将 es 等信息从 origin configmap中赋值到新的 configmap
- 回收:每 2 分钟一次,获取 monitor下的所有 pod 和 configmap,根据 label 中的原始 pod 信息,获取原始 pod,如果原始 pod 不存在,则删除该 agent pod
- 如果用户反复开关采集功能,不需要反复 删除重建 pod或创建 configmap,只需要更新 configmap 中的 stop 字段,fluent-bit就会停止采集
说点什么
欢迎讨论