Contents
概述
k8s版本: 1.13.10
代码路径: https://github.com/kubernetes/kubernetes/tree/v1.12.0/cmd/kubelet
代码走读的路线是:从kubernetes/cmd/kubelet开始,这里包括了kubelet的参数解析、初始化、依赖组件等,然后到达kubernetes/pkg/kubelet模块,开始kubelet的核心逻辑
下面的图汇总了kubelet从初始化到Run成功后,整个都处于运行中的goRoutines。就是靠这些goRoutine的紧密协作,保障了pod整个生命周期中,完全按照我们的要求来运行。下图来源为;ljchen
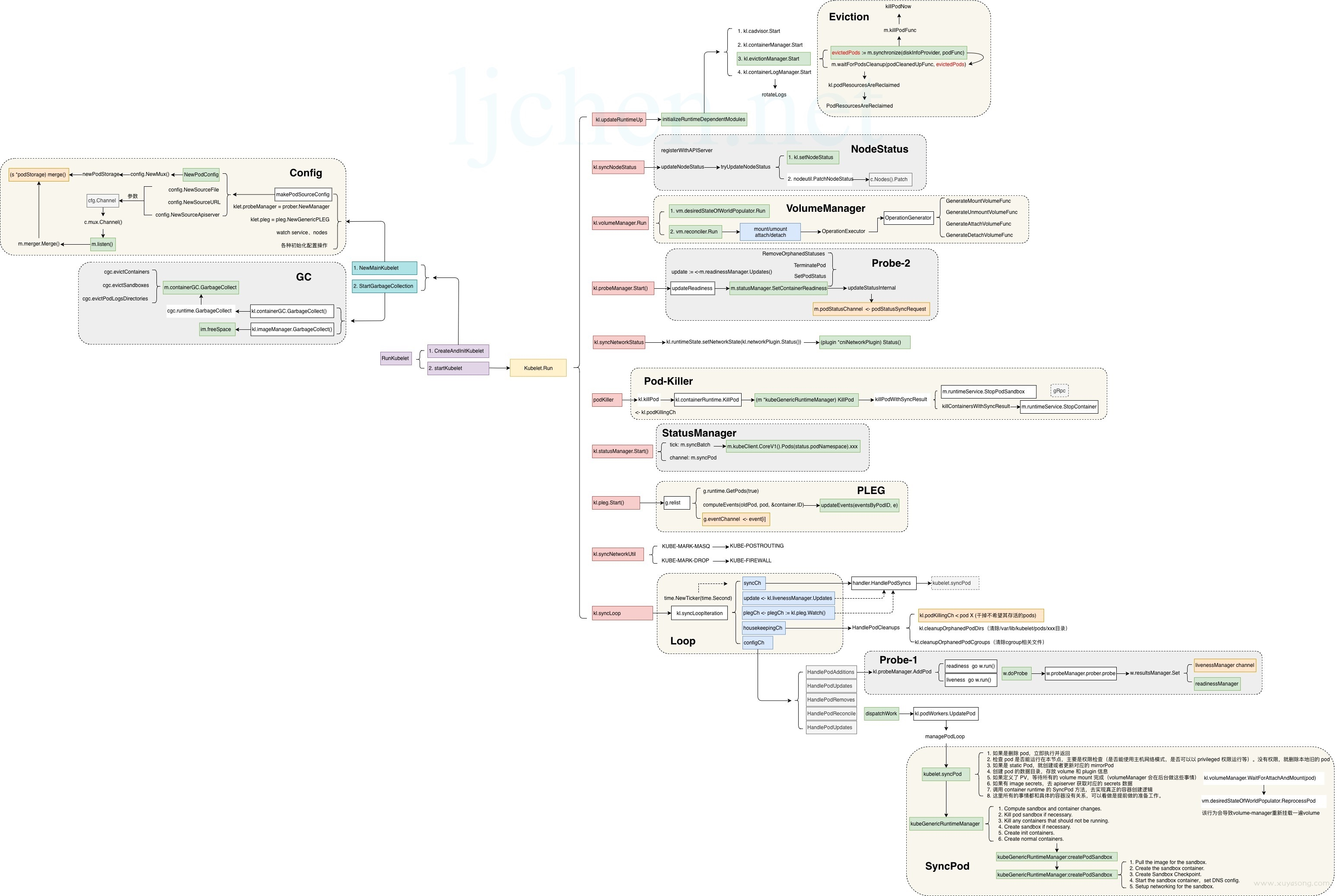
核心流程为红色部分:
- updateRuntimeUp:主要涉及eviction操作
-
syncNodeStatus:将节点注册到k8s集群,并收集节点信息定期上报到api-server
-
volumeManager:容器的镜像挂载、解绑等逻辑,保障存储与容器状态一致
-
probeManager:主要涉及liveness和readiness的逻辑
-
syncNetworkStatus:从CNI plugin获取状态
-
podKiller:用于pod销毁的goRoutine
-
statusManager:负责将Pod状态及时更新到Api-Server
-
pleg: 全称是Pod Lifecycle Event Generator,主要负责将Pod状态变化记录event以及触发Pod同步
-
syncNetworkUtil:配置节点的防火墙和Masquerade
-
syncLoop: kubelet的核心主循环,响应各个模块的channel消息,并集中处理pod状态
在1.13的版本中,kubelet 大约有 13 个manager来保证 pod正常运行
- certificateManager
- cgroupManager
- containerManager
- cpuManager
- nodeContainerManager
- configmapManager
- containerReferenceManager
- evictionManager
- nvidiaGpuManager
- imageGCManager
- kuberuntimeManager
- hostportManager
- podManager
- proberManager
- secretManager
- statusManager
- volumeManager
- tokenManager
本文主要看入口方法和pod的新建逻辑。
cmd入口
cmd 文件夹是kubelet启动的入口,包括了启动参数的解析等,代码目录结构如下:
kubernetes/cmd/kubelet:
.
├── BUILD
├── OWNERS
├── app
│ ├── BUILD
│ ├── OWNERS
│ ├── auth.go
│ ├── init_others.go
│ ├── init_windows.go
│ ├── options # 包括kubelet使用到的option
│ │ ├── BUILD
│ │ ├── container_runtime.go
│ │ ├── globalflags.go
│ │ ├── globalflags_linux.go
│ │ ├── globalflags_other.go
│ │ ├── options.go # 包括KubeletFlags、AddFlags、AddKubeletConfigFlags等
│ │ ├── options_test.go
│ │ ├── osflags_others.go
│ │ └── osflags_windows.go
│ ├── plugins.go
│ ├── server.go # 包括NewKubeletCommand、Run、RunKubelet、CreateAndInitKubelet、startKubelet等
│ ├── server_linux.go
│ ├── server_test.go
│ └── server_unsupported.go
└── kubelet.go # kubelet的main入口函数
在 kubelet.go 文件的注释中就解释了 kubelet 的作用:
kubelet二进制文件负责维护特定主机VM上的一组容器,它同步来自配置文件和etcd的数据,然后它查询Docker以查看当前运行的是什么,通过启动或停止Docker容器来运行一组pod,并同步配置数据给 docker。
kubelet.go: main入口函数,使用cobra作为命令行库
func main() {
rand.Seed(time.Now().UnixNano())
command := app.NewKubeletCommand(server.SetupSignalHandler())
logs.InitLogs()
defer logs.FlushLogs()
if err := command.Execute(); err != nil {
fmt.Fprintf(os.Stderr, "%v\n", err)
os.Exit(1)
}
}
server.go: 做参数初始化和校验,通过对各种特定参数的解析,最终生成kubeletFlags和kubeletConfig两个重要的参数对象,用来构造kubeletServer和其他需求。
// 使用kubeletFlags和kubeletConfig构造KubeletServer对象
kubeletServer := &options.KubeletServer{
KubeletFlags: *kubeletFlags,
KubeletConfiguration: *kubeletConfig,
}
kubeletFlags和kubeletConfig的含义可以参考[kubelet 先导篇],是 1.10 版本之后 kubelet 对配置的一次重新定义,Flags是机器独占参数,config 是可以共享的参数,可以用于动态更新 kubelet
如果开启了docker shim参数,则执行RunDockershim。
// 如果开启了,就运行docker shim
if kubeletServer.KubeletFlags.ExperimentalDockershim {
if err := RunDockershim(&kubeletServer.KubeletFlags, kubeletConfig, stopCh); err != nil {
glog.Fatal(err)
}
return
}
运行kubelet并且不退出。由Run函数进入后续的操作。
glog.V(5).Infof("KubeletConfiguration: %#v", kubeletServer.KubeletConfiguration)
if err := Run(kubeletServer, kubeletDeps, stopCh); err != nil {
glog.Fatal(err)
}
Run方法:
func Run(s *options.KubeletServer, kubeDeps *kubelet.Dependencies, stopCh <-chan struct{}) error {
glog.Infof("Version: %+v", version.Get())
if err := initForOS(s.KubeletFlags.WindowsService); err != nil {
return fmt.Errorf("failed OS init: %v", err)
}
if err := run(s, kubeDeps, stopCh); err != nil {
return fmt.Errorf("failed to run Kubelet: %v", err)
}
return nil
}
构造kubeDeps,包括KubeClient,CSIClient,CAdvisor等,初始化后,被 kubelet 的 server 使用
return &kubelet.Dependencies{
Auth: nil, // default does not enforce auth[nz]
CAdvisorInterface: nil, // cadvisor.New launches background processes (bg http.ListenAndServe, and some bg cleaners), not set here
Cloud: nil, // cloud provider might start background processes
ContainerManager: nil,
DockerClientConfig: dockerClientConfig,
KubeClient: nil,
HeartbeatClient: nil,
CSIClient: nil,
EventClient: nil,
Mounter: mounter,
OOMAdjuster: oom.NewOOMAdjuster(),
OSInterface: kubecontainer.RealOS{},
VolumePlugins: ProbeVolumePlugins(),
DynamicPluginProber: GetDynamicPluginProber(s.VolumePluginDir, pluginRunner),
TLSOptions: tlsOptions}, nil
}
RunKubelet函数核心代码为执行了CreateAndInitKubelet和startKubelet两个函数的操作,以下对这两个函数进行分析。
CreateAndInitKubelet方法:
k, err := CreateAndInitKubelet(&kubeServer.KubeletConfiguration,
kubeDeps,
&kubeServer.ContainerRuntimeOptions,
kubeServer.ContainerRuntime,
kubeServer.RuntimeCgroups,
kubeServer.HostnameOverride,
kubeServer.NodeIP,
kubeServer.ProviderID,
kubeServer.CloudProvider,
kubeServer.CertDirectory,
kubeServer.RootDirectory,
kubeServer.RegisterNode,
kubeServer.RegisterWithTaints,
kubeServer.AllowedUnsafeSysctls,
kubeServer.RemoteRuntimeEndpoint,
kubeServer.RemoteImageEndpoint,
kubeServer.ExperimentalMounterPath,
kubeServer.ExperimentalKernelMemcgNotification,
kubeServer.ExperimentalCheckNodeCapabilitiesBeforeMount,
kubeServer.ExperimentalNodeAllocatableIgnoreEvictionThreshold,
kubeServer.MinimumGCAge,
kubeServer.MaxPerPodContainerCount,
kubeServer.MaxContainerCount,
kubeServer.MasterServiceNamespace,
kubeServer.RegisterSchedulable,
kubeServer.NonMasqueradeCIDR,
kubeServer.KeepTerminatedPodVolumes,
kubeServer.NodeLabels,
kubeServer.SeccompProfileRoot,
kubeServer.BootstrapCheckpointPath,
kubeServer.NodeStatusMaxImages)
if err != nil {
return fmt.Errorf("failed to create kubelet: %v", err)
}
NewMainKubelet–>PodConfig–>NewPodConfig–>kubetypes.PodUpdate。会生成一个podUpdate的channel来监听pod的变化,该channel会在k.Run(podCfg.Updates())中作为关键入参。
if kubeDeps.PodConfig == nil {
return fmt.Errorf("failed to create kubelet, pod source config was nil")
}
podCfg := kubeDeps.PodConfig
rlimit.RlimitNumFiles(uint64(kubeServer.MaxOpenFiles))
// 如果设置了只运行一次的参数,则执行k.RunOnce,否则执行核心函数startKubelet。具体实现如下:
if runOnce {
if _, err := k.RunOnce(podCfg.Updates()); err != nil {
return fmt.Errorf("runonce failed: %v", err)
}
klog.Infof("Started kubelet as runonce")
else {
startKubelet(k, podCfg, &kubeServer.KubeletConfiguration, kubeDeps, kubeServer.EnableServer)
klog.Infof("Started kubelet")
}
startKubelet方法:
func startKubelet(k kubelet.Bootstrap, podCfg *config.PodConfig, kubeCfg *kubeletconfiginternal.KubeletConfiguration, kubeDeps *kubelet.Dependencies, enableServer bool) {
// start the kubelet
go wait.Until(func() {
k.Run(podCfg.Updates())
}, 0, wait.NeverStop)
// start the kubelet server
if enableServer {
go k.ListenAndServe(net.ParseIP(kubeCfg.Address), uint(kubeCfg.Port), kubeDeps.TLSOptions, kubeDeps.Auth, kubeCfg.EnableDebuggingHandlers, kubeCfg.EnableContentionProfiling)
}
if kubeCfg.ReadOnlyPort > 0 {
go k.ListenAndServeReadOnly(net.ParseIP(kubeCfg.Address), uint(kubeCfg.ReadOnlyPort))
}
}
通过长驻进程的方式运行k.Run,不退出,kubelet.Bootstrap是引入了kubernetes/pkg/kubelet/kubelet.go,将实际运行逻辑转移到了 pkg 目录下。
kubelet 主方法
位于 pkg/kubelet/kubelet.go 文件
Bootstrap定义了kubelet 拥有的方法,被 cmd 层的 server.go调用,ListenAndServe就是其中一个
type Bootstrap interface {
GetConfiguration() kubeletconfiginternal.KubeletConfiguration
BirthCry()
StartGarbageCollection()
ListenAndServe(address net.IP, port uint, tlsOptions *server.TLSOptions, auth server.AuthInterface, enableDebuggingHandlers, enableContentionProfiling bool)
ListenAndServeReadOnly(address net.IP, port uint)
ListenAndServePodResources()
Run(<-chan kubetypes.PodUpdate)
RunOnce(<-chan kubetypes.PodUpdate) ([]RunPodResult, error)
}
kubelet 初始化了很多manager,用于处理 pod 生命周期中的各种操作,如 oom 判断,secret、configmap 处理、liveness判断等。。
- containerRefManager
- oomWatcher
- klet.secretManager
- klet.configMapManager
- klet.livenessManager
- klet.podManager
- klet.resourceAnalyzer
- imageManager
- klet.statusManager
- klet.volumeManager
- eviction.NewManager
目前pod所使用的runtime只有docker和remote两种,rkt已经废弃。
if containerRuntime == "rkt" {
klog.Fatalln("rktnetes has been deprecated in favor of rktlet. Please see https://github.com/kubernetes-incubator/rktlet for more information.")
}
当runtime是docker的时候,会执行docker相关操作。
switch containerRuntime {
case kubetypes.DockerContainerRuntime:
streamingConfig := getStreamingConfig(kubeCfg, kubeDeps, crOptions)
ds, err := dockershim.NewDockerService(kubeDeps.DockerClientConfig, crOptions.PodSandboxImage, streamingConfig,
&pluginSettings, runtimeCgroups, kubeCfg.CgroupDriver, crOptions.DockershimRootDirectory, !crOptions.RedirectContainerStreaming)
if err != nil {
return nil, err
}
if err := server.Start(); err != nil {
return nil, err
}
...
kubelet 的工作核心就是在围绕着不同的生产者生产出来的不同的有关 pod 的消息来调用相应的消费者(不同的子模块)完成不同的行为(创建和删除 pod 等),即图中的控制循环(SyncLoop),通过不同的事件驱动这个控制循环运行。
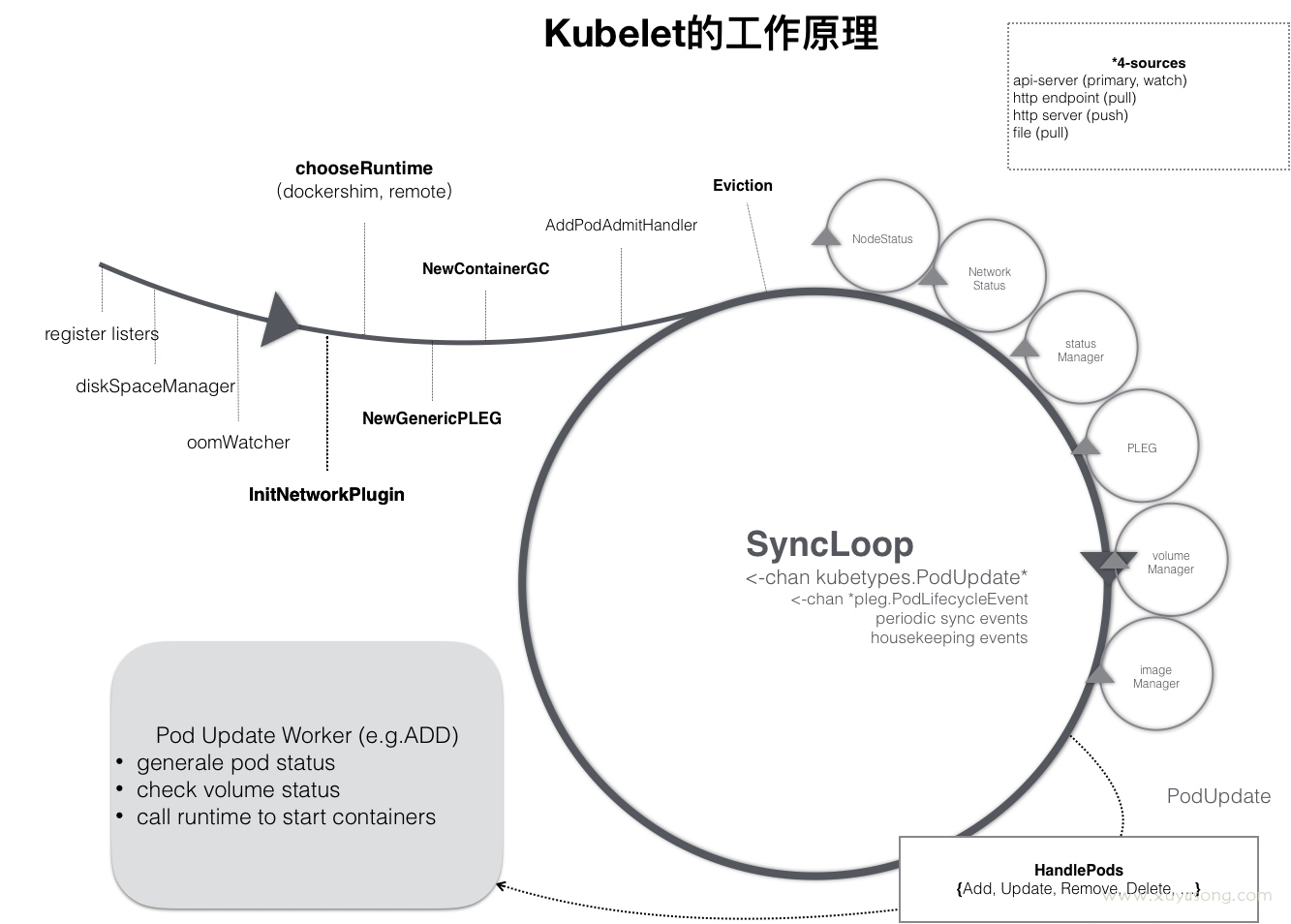
pod处理逻辑
调用路径
当一个 pod 完成调度,与一个 node 绑定起来之后,这个 pod 就会触发 kubelet 在循环控制里注册的 handler,上图中的 HandlePods 部分。
此时,通过检查 pod 在 kubelet 内存中的状态,kubelet 就能判断出这是一个新调度过来的 pod,从而触发 Handler 里的 ADD 事件对应的逻辑处理。然后 kubelet 会为这个 pod 生成对应的 podStatus,接着检查 pod 所声明的 volume 是不是准备好了,然后调用下层的容器运行时。如果是 update 事件的话,kubelet 就会根据 pod 对象具体的变更情况,调用下层的容器运行时进行容器的重建。


podWorker主要用来对pod相应事件进行处理和同步,包含以下三个方法:UpdatePod、ForgetNonExistingPodWorkers、ForgetWorker。
type PodWorkers interface {
UpdatePod(options *UpdatePodOptions)
ForgetNonExistingPodWorkers(desiredPods map[types.UID]empty)
ForgetWorker(uid types.UID)
}
完整调用路径:
main —> NewKubeletCommand —> Run(kubeletServer..) —> run(s, kubeDeps, stopCh) —> RunKubelet(s, kubeDeps, s.RunOnce) —> startKubelet —> k.Run(podCfg.Updates()) / k.ListenAndServe —> (kl *Kubelet) Run —> kl.pleg.Start() / kl.syncLoop(updates, kl) —> syncLoopIteration
kubelet的控制循环syncLoop
syncLoop对pod的生命周期进行管理,其中syncLoop调用了syncLoopIteration函数,该函数根据podUpdate的信息,针对不同的操作,由SyncHandler来执行pod的增删改查等生命周期的管理,其中的syncHandler包括HandlePodSyncs和HandlePodCleanups等。
即使没有需要更新的 pod 配置,kubelet 也会定时去做同步和清理 pod 的工作。然后在 for 循环中一直调用 syncLoopIteration,如果在每次循环过程中出现比较严重的错误,kubelet 会记录到 runtimeState 中,遇到错误就等待 5 秒中继续循环。
syncLoopIteration实际执行了pod的操作,此部分设置了几种不同的channel:
- configCh:该信息源由 kubeDeps 对象中的 PodConfig 子模块提供,该模块将同时 watch 3 个不同来源的 pod 信息的变化(file,http,apiserver),一旦某个来源的 pod 信息发生了更新(创建/更新/删除),这个 channel 中就会出现被更新的 pod 信息和更新的具体操作。
- syncCh:定时器管道,每隔一秒去同步最新保存的 pod 状态
- houseKeepingCh:housekeeping 事件的管道,做 pod 清理工作
- plegCh:该信息源由 kubelet 对象中的 pleg 子模块提供,该模块主要用于周期性地向 container runtime 查询当前所有容器的状态,如果状态发生变化,则这个 channel 产生事件。
- livenessManager.Updates():健康检查发现某个 pod 不可用,kubelet 将根据 Pod 的restartPolicy 自动执行正确的操作
syncLoopIteration方法内容如下:
func (kl *Kubelet) syncLoopIteration(configCh <-chan kubetypes.PodUpdate, handler SyncHandler,
syncCh <-chan time.Time, housekeepingCh <-chan time.Time, plegCh <-chan *pleg.PodLifecycleEvent) bool {
select {
case u, open := <-configCh:
if !open {
glog.Errorf("Update channel is closed. Exiting the sync loop.")
return false
}
switch u.Op {
case kubetypes.ADD:
...
case kubetypes.UPDATE:
...
case kubetypes.REMOVE:
...
case kubetypes.RECONCILE:
...
case kubetypes.DELETE:
...
case kubetypes.RESTORE:
...
case kubetypes.SET:
...
}
...
case e := <-plegCh:
...
case <-syncCh:
...
case update := <-kl.livenessManager.Updates():
...
case <-housekeepingCh:
...
}
return true
}
pod新增:HandlePodAdditions
- 先根据pod创建时间对pod进行排序,然后遍历pod列表,来执行pod的相关操作。
func (kl *Kubelet) HandlePodAdditions(pods []*v1.Pod) {
start := kl.clock.Now()
sort.Sort(sliceutils.PodsByCreationTime(pods))
for _, pod := range pods {
...
}
}
- 将pod添加到pod manager中
for _, pod := range pods {
// Responsible for checking limits in resolv.conf
if kl.dnsConfigurer != nil && kl.dnsConfigurer.ResolverConfig != "" {
kl.dnsConfigurer.CheckLimitsForResolvConf()
}
existingPods := kl.podManager.GetPods()
// Always add the pod to the pod manager. Kubelet relies on the pod
// manager as the source of truth for the desired state. If a pod does
// not exist in the pod manager, it means that it has been deleted in
// the apiserver and no action (other than cleanup) is required.
kl.podManager.AddPod(pod)
...
}
- 如果是mirror pod,则对mirror pod进行处理。
if kubepod.IsMirrorPod(pod) {
kl.handleMirrorPod(pod, start)
continue
}
- 如果当前pod的状态不是Terminated状态,则判断是否接受该pod,如果不接受则将pod状态改为Failed。
if !kl.podIsTerminated(pod) {
// Only go through the admission process if the pod is not
// terminated.
// We failed pods that we rejected, so activePods include all admitted
// pods that are alive.
activePods := kl.filterOutTerminatedPods(existingPods)
// Check if we can admit the pod; if not, reject it.
if ok, reason, message := kl.canAdmitPod(activePods, pod); !ok {
kl.rejectPod(pod, reason, message)
continue
}
}
- 执行dispatchWork函数,该函数是syncHandler中调用到的核心函数,该函数在pod worker中启动一个异步循环,来分派pod的相关操作
mirrorPod, _ := kl.podManager.GetMirrorPodByPod(pod)
kl.dispatchWork(pod, kubetypes.SyncPodCreate, mirrorPod, start)
- 最后,在 probeManager 中添加 pod,如果 pod 中定义了 readiness 和 liveness 健康检查,启动 goroutine 定期进行检测
kl.probeManager.AddPod(pod)
pod的清理任务HandlePodCleanups
其中包括terminating的pod,orphaned的pod等。
func (kl *Kubelet) HandlePodCleanups() error {
var (
cgroupPods map[types.UID]cm.CgroupName
err error
)
if kl.cgroupsPerQOS {
pcm := kl.containerManager.NewPodContainerManager()
cgroupPods, err = pcm.GetAllPodsFromCgroups()
if err != nil {
return fmt.Errorf("failed to get list of pods that still exist on cgroup mounts: %v", err)
}
}
...
}
- 列出所有pod包括mirror pod。
activePods := kl.filterOutTerminatedPods(allPods)
desiredPods := make(map[types.UID]empty)
for _, pod := range activePods {
desiredPods[pod.UID] = empty{}
}
- pod worker停止不再存在的pod的任务,并从probe manager中清除pod。
kl.podWorkers.ForgetNonExistingPodWorkers(desiredPods)
kl.probeManager.CleanupPods(activePods)
- 将需要杀死的pod加入到podKillingCh的channel中,podKiller的任务会监听该channel并获取需要杀死的pod列表来执行杀死pod的操作。
runningPods, err := kl.runtimeCache.GetPods()
if err != nil {
glog.Errorf("Error listing containers: %#v", err)
return err
}
for _, pod := range runningPods {
if _, found := desiredPods[pod.ID]; !found {
kl.podKillingCh <- &kubecontainer.PodPair{APIPod: nil, RunningPod: pod}
}
}
- 当pod不再被绑定到该节点,移除podStatus,其中removeOrphanedPodStatuses最后调用的函数是statusManager的RemoveOrphanedStatuses方法。
kl.removeOrphanedPodStatuses(allPods, mirrorPods)
- 移除所有的orphaned volume。
err = kl.cleanupOrphanedPodDirs(allPods, runningPods)
if err != nil {
// We want all cleanup tasks to be run even if one of them failed. So
// we just log an error here and continue other cleanup tasks.
// This also applies to the other clean up tasks.
glog.Errorf("Failed cleaning up orphaned pod directories: %v", err)
}
- 移除mirror pod。
kl.podManager.DeleteOrphanedMirrorPods()
- 删除不再运行的pod的cgroup。
if kl.cgroupsPerQOS {
kl.cleanupOrphanedPodCgroups(cgroupPods, activePods)
}
- 执行垃圾回收(GC)操作。
kl.backOff.GC()
syncHandler
- HandlePodAdditions、HandlePodUpdates、HandlePodReconcile、HandlePodSyncs都调用到了dispatchWork来执行pod的相关操作。
- HandlePodCleanups的pod清理任务,通过channel的方式加需要清理的pod给podKiller来清理。
- syncHandler中使用到pod manager、probe manager、pod worker、podKiller来执行相关操作。
- syncHandler中的各种handler是根据podUpdate中不同的操作类型(增删改查等)来执行具体的handler。
syncHandler主要执行以下的工作流:
- 如果是正在创建的pod,则记录pod worker的启动latency。
- 调用generateAPIPodStatus为pod提供v1.PodStatus信息。
- 如果pod是第一次运行,记录pod的启动latency。
- 更新status manager中的pod状态。
- 如果pod不应该被运行则杀死pod。
- 如果pod是一个static pod,并且没有对应的mirror pod,则创建一个mirror pod。
- 如果没有pod的数据目录则给pod创建对应的数据目录。
- 等待volume被attach或mount。
- 获取pod的secret数据。
- 调用container runtime的SyncPod函数,执行相关pod操作。
- 更新pod的ingress和egress的traffic limit。
- 当以上任务流中有任何的error,则return error。在下一次执行syncPod的任务流会被再次执行。对于错误信息会被记录到event中,方便debug。
pod worker中有一个managePodLoop方法,调用了syncPodFn,而syncPodFn实际就是kubelet.SyncPod,也就是 经典的pod 的控制循环
SyncPod
基础概念:
Pod只是一个逻辑概念,他实际操作的还是容器运行时如 docker,然后操作 cgroup、linux namespace。
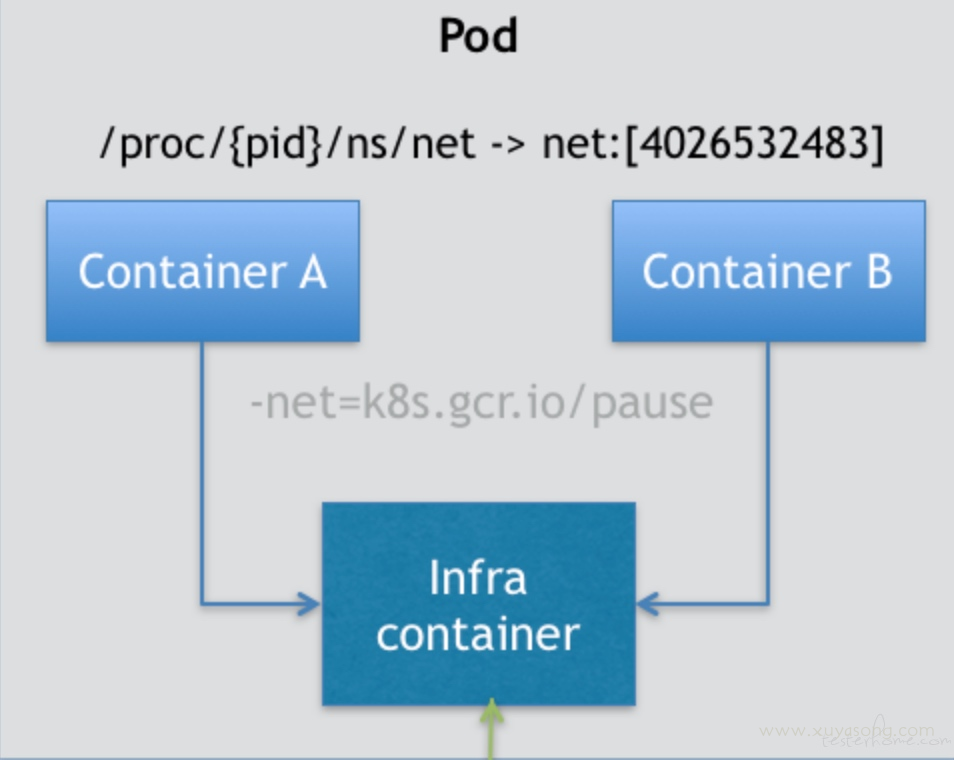
如上图所示,Pod 里有两个用户容器 A 和 B,还有一个infra container, 它也叫做pause容器,也被称为sandbox,意思是沙箱,这个沙箱为其他容器提供共享的网络和文件挂载资源。当这个容器被创建出来并hold住Network Namespace之后,其他由用户自己定义的容器就可以通过container模式加入到这个容器的Network Namespace中。这也就意味着,对于在一个POD中的容器A和容器B来说,他们拥有相同的IP地址,可以通过localhost进行互相通信。
创建 pod
SyncPod主要执行sync操作使得运行的pod达到期望状态的pod。主要执行以下操作:
- 计算 Pod 中沙盒和容器的变更;
- 强制停止 Pod 对应的沙盒;
- 强制停止所有不应该运行的容器;
- 为 Pod 创建新的沙盒;
- 创建 Pod 规格中指定的初始化容器;
- 依次创建 Pod 规格中指定的常规容器;
概况就是:首先计算 Pod 规格和沙箱的变更,然后停止可能影响这一次创建或者更新的容器,最后依次创建沙盒、初始化容器和常规容器。
如创建 pod 逻辑:
func (m *kubeGenericRuntimeManager) SyncPod(pod *v1.Pod, _ v1.PodStatus, podStatus *kubecontainer.PodStatus, pullSecrets []v1.Secret, backOff *flowcontrol.Backoff) (result kubecontainer.PodSyncResult) {
podContainerChanges := m.computePodActions(pod, podStatus)
if podContainerChanges.CreateSandbox {
ref, _ := ref.GetReference(legacyscheme.Scheme, pod)
}
if podContainerChanges.KillPod {
if podContainerChanges.CreateSandbox {
m.purgeInitContainers(pod, podStatus)
}
} else {
for containerID, containerInfo := range podContainerChanges.ContainersToKill {
m.killContainer(pod, containerID, containerInfo.name, containerInfo.message, nil) }
}
}
podSandboxID := podContainerChanges.SandboxID
if podContainerChanges.CreateSandbox {
podSandboxID, _, _ = m.createPodSandbox(pod, podContainerChanges.Attempt)
}
podSandboxConfig, _ := m.generatePodSandboxConfig(pod, podContainerChanges.Attempt)
if container := podContainerChanges.NextInitContainerToStart; container != nil {
msg, _ := m.startContainer(podSandboxID, podSandboxConfig, container, pod, podStatus, pullSecrets, podIP, kubecontainer.ContainerTypeInit)
}
for _, idx := range podContainerChanges.ContainersToStart {
container := &pod.Spec.Containers[idx]
msg, _ := m.startContainer(podSandboxID, podSandboxConfig, container, pod, podStatus, pullSecrets, podIP, kubecontainer.ContainerTypeRegular)
}
return
}
初始化容器和常规容器调用 startContainer 来启动:
func (m *kubeGenericRuntimeManager) startContainer(podSandboxID string, podSandboxConfig *runtimeapi.PodSandboxConfig, container *v1.Container, pod *v1.Pod, podStatus *kubecontainer.PodStatus, pullSecrets []v1.Secret, podIP string, containerType kubecontainer.ContainerType) (string, error) {
imageRef, _, _ := m.imagePuller.EnsureImageExists(pod, container, pullSecrets)
// ...
containerID, _ := m.runtimeService.CreateContainer(podSandboxID, containerConfig, podSandboxConfig)
m.internalLifecycle.PreStartContainer(pod, container, containerID)
m.runtimeService.StartContainer(containerID)
if container.Lifecycle != nil && container.Lifecycle.PostStart != nil {
kubeContainerID := kubecontainer.ContainerID{
Type: m.runtimeName,
ID: containerID,
}
msg, _ := m.runner.Run(kubeContainerID, pod, container, container.Lifecycle.PostStart)
}
return "", nil
}
在启动每一个容器的过程中也都按照相同的步骤进行操作:
- 通过镜像拉取器获得当前容器中使用镜像的引用;
- 调用远程的 runtimeService 创建容器;
- 调用内部的生命周期方法 PreStartContainer 为当前的容器设置分配的 CPU 等资源;
- 调用远程的 runtimeService 开始运行镜像;
- 如果当前的容器包含 PostStart 钩子就会执行该回调;
- 每次 SyncPod 被调用时不一定是创建新的 Pod 对象,它还会承担更新、删除和同步 Pod 规格的职能,根据输入的新规格执行相应的操作。
健康检查
pod 创建好之后,如果我们配置了livenessProbe或者readinessProbe,健康检查的 handler 就出场了。
在 Pod 被创建或者被移除时,会被加入到当前节点上的 ProbeManager 中,ProbeManager 会负责这些 Pod 的健康检查,也就是刚刚提到的HandlePodAdditions和HandlePodRemoves方法
func (kl *Kubelet) HandlePodAdditions(pods []*v1.Pod) {
start := kl.clock.Now()
for _, pod := range pods {
kl.podManager.AddPod(pod)
kl.dispatchWork(pod, kubetypes.SyncPodCreate, mirrorPod, start)
kl.probeManager.AddPod(pod)
}
}
func (kl *Kubelet) HandlePodRemoves(pods []*v1.Pod) {
start := kl.clock.Now()
for _, pod := range pods {
kl.podManager.DeletePod(pod)
kl.deletePod(pod)
kl.probeManager.RemovePod(pod)
}
}
每一个新的 Pod 都会被调用 ProbeManager 的AddPod 函数,这个方法会初始化一个新的 Goroutine 并在其中运行对当前 Pod 进行健康检查:
func (m *manager) AddPod(pod *v1.Pod) {
key := probeKey{podUID: pod.UID}
for _, c := range pod.Spec.Containers {
key.containerName = c.Name
if c.ReadinessProbe != nil {
key.probeType = readiness
w := newWorker(m, readiness, pod, c)
m.workers[key] = w
go w.run()
}
if c.LivenessProbe != nil {
key.probeType = liveness
w := newWorker(m, liveness, pod, c)
m.workers[key] = w
go w.run()
}
}
}
删除 pod
Kubelet 在 HandlePodRemoves 方法处理删除逻辑,最终会通知PodKiller,并调用deletePod方法
func (kl *Kubelet) deletePod(pod *v1.Pod) error {
kl.podWorkers.ForgetWorker(pod.UID)
runningPods, _ := kl.runtimeCache.GetPods()
runningPod := kubecontainer.Pods(runningPods).FindPod("", pod.UID)
podPair := kubecontainer.PodPair{APIPod: pod, RunningPod: &runningPod}
kl.podKillingCh <- &podPair
return nil
}
Kubelet 除了将事件通知给 PodKiller 之外,还需要将当前 Pod 对应的 Worker 从持有的 podWorkers 中删除
经过一系列的方法调用之后,最终调用容器运行时的 killContainersWithSyncResult 方法,这个方法会同步地杀掉当前 Pod 中全部的容器:
func (m *kubeGenericRuntimeManager) killContainersWithSyncResult(pod *v1.Pod, runningPod kubecontainer.Pod, gracePeriodOverride *int64) (syncResults []*kubecontainer.SyncResult) {
containerResults := make(chan *kubecontainer.SyncResult, len(runningPod.Containers))
for _, container := range runningPod.Containers {
go func(container *kubecontainer.Container) {
killContainerResult := kubecontainer.NewSyncResult(kubecontainer.KillContainer, container.Name)
m.killContainer(pod, container.ID, container.Name, "Need to kill Pod", gracePeriodOverride)
containerResults <- killContainerResult
}(container)
}
close(containerResults)
for containerResult := range containerResults {
syncResults = append(syncResults, containerResult)
}
return
}
对于每一个容器来说,它们在被停止之前都会先调用PreStop 的钩子方法,让容器中的应用程序能够有时间完成一些未处理的操作,随后调用远程的服务停止运行的容器:
func (m *kubeGenericRuntimeManager) killContainer(pod *v1.Pod, containerID kubecontainer.ContainerID, containerName string, reason string, gracePeriodOverride *int64) error {
containerSpec := kubecontainer.GetContainerSpec(pod, containerName);
gracePeriod := int64(minimumGracePeriodInSeconds)
switch {
case pod.DeletionGracePeriodSeconds != nil:
gracePeriod = *pod.DeletionGracePeriodSeconds
case pod.Spec.TerminationGracePeriodSeconds != nil:
gracePeriod = *pod.Spec.TerminationGracePeriodSeconds
}
m.executePreStopHook(pod, containerID, containerSpec, gracePeriod
m.internalLifecycle.PreStopContainer(containerID.ID)
m.runtimeService.StopContainer(containerID.ID, gracePeriod)
m.containerRefManager.ClearRef(containerID)
return err
}
说点什么
2 评论 在 "kubelet 原理解析一:podManager"
test
[…] statusManager 和 probeManager,这两个都是和 pod 状态相关的逻辑,在kubelet 原理解析一:pod管理文章中有提到,statusManager […]