Contents
一. 概述
本文是kubelet源码阅读的先导片,先了解kubelet的主要配置和功能以及一些注意事项,后面走读源码的时候才会更加顺畅,不然一堆 config 的初始化和chan处理,不知道支持哪些新特性,啥场景会用到,看了也没啥意思。
二. 配置方式
2.1 flag 模式
k8s 迭代速度很快,几个月一个大版本,kubelet 的启动参数也在不断变化,一切配置以官方文档为准,或者拿二进制直接–help 看,不然忙活一圈才发现某个特性在当前版本不支持。下面是一份基础可用的kubelet配置,版本 1.8
./kubelet \
--address=192.168.5.228 \
--allow-privileged=true \
--client-ca-file=/etc/kubernetes/pki/ca.pem \
--cloud-config=/etc/kubernetes/cloud.config \
--cloud-provider=external \
--cluster-dns=172.16.0.10 \
--cluster-domain=cluster.local \
--docker-root=/data/docker \
--fail-swap-on=false \
--feature-gates=VolumeSnapshotDataSource=true,CSINodeInfo=true,CSIDriverRegistry=true \
--hostname-override=192.168.5.228 \
--kubeconfig=/etc/kubernetes/kubelet.conf \
--logtostderr=true \
--network-plugin=kubenet \
--max-pods=256 \
--non-masquerade-cidr=172.26.0.0/16 \
--pod-infra-container-image=hub.docker.com/public/pause:2.0 \
--pod-manifest-path=/etc/kubernetes/manifests \
--root-dir=/data/kubelet \
--tls-cipher-suites=TLS_ECDHE_RSA_WITH_AES_128_GCM_SHA256,TLS_ECDHE_RSA_WITH_AES_256_GCM_SHA384,TLS_ECDHE_RSA_WITH_CHACHA20_POLY1305,TLS_RSA_WITH_AES_128_CBC_SHA,TLS_RSA_WITH_AES_256_CBC_SHA,TLS_RSA_WITH_AES_128_GCM_SHA256,TLS_RSA_WITH_AES_256_GCM_SHA384,TLS_ECDHE_RSA_WITH_AES_256_CBC_SHA \
--anonymous-auth=false \
--v=5 \
--enforce-node-allocatable=pods,kube-reserved,system-reserved \
--kube-reserved-cgroup=/system.slice/kubelet.service \
--system-reserved-cgroup=/system.slice \
--kube-reserved=cpu=50m \
--system-reserved=cpu=50m \
--eviction-hard=memory.available<5%,nodefs.available<10%,imagefs.available<10%% \
--eviction-soft=memory.available<10%,nodefs.available<15%,imagefs.available<15%% \
--eviction-soft-grace-period=memory.available=2m,nodefs.available=2m,imagefs.available=2m \
--eviction-max-pod-grace-period=30 \
--eviction-minimum-reclaim=memory.available=0Mi,nodefs.available=500Mi,imagefs.available=500Mi
2.2 config 模式
上面的配置文件是老版本 kubelet(1.10 以前),启动参数都是用 flag 来声明的,简单粗暴,在 1.10 以后,kubelet 支持了KubeletConfiguration的方式来声明参数,如 kubeadm 部署的集群配置如下:
# Note: This dropin only works with kubeadm and kubelet v1.11+
[Service]
Environment="KUBELET_KUBECONFIG_ARGS=--bootstrap-kubeconfig=/etc/kubernetes/bootstrap-kubelet.conf --kubeconfig=/etc/kubernetes/kubelet.conf"
Environment="KUBELET_CONFIG_ARGS=--config=/var/lib/kubelet/config.yaml"
# This is a file that "kubeadm init" and "kubeadm join" generates at runtime, populating the KUBELET_KUBEADM_ARGS variable dynamically
EnvironmentFile=-/var/lib/kubelet/kubeadm-flags.env
# This is a file that the user can use for overrides of the kubelet args as a last resort. Preferably, the user should use
# the .NodeRegistration.KubeletExtraArgs object in the configuration files instead. KUBELET_EXTRA_ARGS should be sourced from this file.
EnvironmentFile=-/etc/sysconfig/kubelet
ExecStart=
ExecStart=/usr/bin/kubelet $KUBELET_KUBECONFIG_ARGS $KUBELET_CONFIG_ARGS $KUBELET_KUBEADM_ARGS $KUBELET_EXTRA_ARGS
~
kubelet 的--config配置采用了本地文件KubeletConfiguration资源做参数
本地文件/var/lib/kubelet/config.yaml内容为:
apiVersion: kubelet.config.k8s.io/v1beta1
authentication:
anonymous:
enabled: false
webhook:
cacheTTL: 0s
enabled: true
x509:
clientCAFile: /etc/kubernetes/pki/ca.crt
authorization:
mode: Webhook
webhook:
cacheAuthorizedTTL: 0s
cacheUnauthorizedTTL: 0s
clusterDNS:
- 10.96.0.10
clusterDomain: cluster.local
cpuManagerReconcilePeriod: 0s
evictionPressureTransitionPeriod: 0s
fileCheckFrequency: 0s
healthzBindAddress: 127.0.0.1
healthzPort: 10248
httpCheckFrequency: 0s
imageMinimumGCAge: 0s
kind: KubeletConfiguration
nodeStatusReportFrequency: 0s
nodeStatusUpdateFrequency: 0s
rotateCertificates: true
runtimeRequestTimeout: 0s
staticPodPath: /etc/kubernetes/manifests
streamingConnectionIdleTimeout: 0s
syncFrequency: 0s
volumeStatsAggPeriod: 0s
为什么要这么改呢?
--max-pods int32 Number of Pods that can run on this Kubelet. (default 110) (DEPRECATED: This parameter should be set via the config file specified by the Kubelet's --config flag. See https://kubernetes.io/docs/tasks/administer-cluster/kubelet-config-file/ for more information.)
以上面的max-pods配置为例,你运行kubelet --help你会发现,kubelet的绝大多数命令行flag参数都被DEPRECATED了,后面一句就是官方推荐我们使用--config文件来指定这些配置,具体内容可以查看这里Set Kubelet parameters via a config file,一来是区分出什么是机器特有配置,什么是机器可以共享的配置,二来是为了支持之后更高级的动态Kubelet配置Dynamic Kubelet Configuration,即把可以共享的配置做成一种资源,节点共享一份配置
2.3 动态 config 模式
kubelet 的支持动态 kubelet 配置,即dynamic-config,在1.11版本开始支持,原理如下:
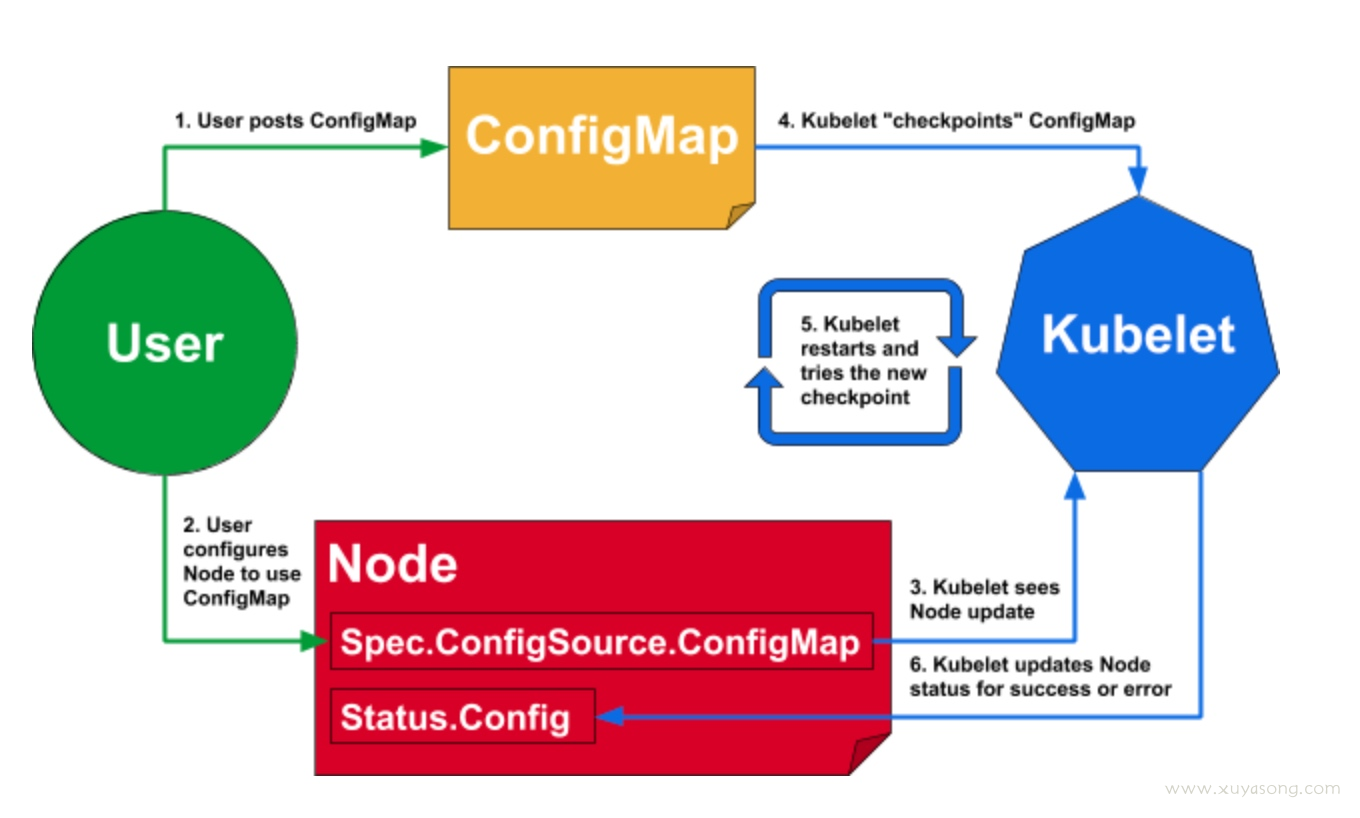
参考:https://kubernetes.io/docs/tasks/administer-cluster/reconfigure-kubelet/
config 文件的概念出来之后,kubelet 的配置就划分为了两部分:
- KubeletFlag: 指那些不允许在kubelet运行时进行修改的配置集,或者不能在集群中各个Nodes之间共享的配置集。直接以 flag 的形式添加,如nodeip
- KubeletConfiguration: 指可以在集群中各个Nodes之间共享的配置集。

动态配置在 1.17仍然处于 beta 状态,其中有几个关键点还没解决:
- 没有提供原生的集群灰度能力,需要用户自己实现自动化灰度节点配置。如果所有Node引用同一个Kubelet ConfigMap,当该ConfigMap发生错误变更后,可能会导致集群短时间不可用。
- 分批灰度所有Nodes的能力
- 或者是滚动灰度所有Nodes的能力
- 哪些集群配置可以通过Kubelet Dynamic Config安全可靠的动态变更,还没有一个完全明确的集合。通常情况下,我们可以参考staging/src/k8s.io/kubelet/config/v1beta1/types.go:62中对KubeletConfiguration的定义注解了解那些Dynamic Config,但是还是建议在测试集群中测试过后,再通过Dynamic Config灰度到生产环境。
三.参数含义
无论是flag 参数还是 config 参数,都是kubelet 运行的必备条件,这里对一些关键指标进行解释,以下内容大量引用官方文档
全部 config:https://kubernetes.io/zh/docs/reference/command-line-tools-reference/kubelet/
config 文件中的参数列表为:https://github.com/kubernetes/kubernetes/blob/master/staging/src/k8s.io/kubelet/config/v1beta1/types.go
剩下的就是 flag参数,参数的示例值见上文。
3.1 flag 参数
cloud-config: 云服务商的配置文件路径,cloud-provider开启时使用cloud-provider: 云服务商,为空表示没有云服务商,用于确定节点名称。hostname-override: 如果为非空,将使用此字符串而不是实际的主机名作为节点标识config: 用于声明 config 文件的路径container-runtime: 容器运行时,默认为 docker,还支持remote、rkt(已弃用)docker-root: docker 根目录的路径,默认值:/var/lib/dockerkubeconfig: kubeconfig 配置文件的路径,指定如何连接到 API 服务器。提供 --kubeconfig 将启用 API 服务器模式,而省略 --kubeconfig 将启用独立模式。logtostderr: 日志输出到 stderr 而不是文件(默认值为 true)network-plugin: 仅当容器运行环境设置为 docker 时生效,如 kubenetnon-masquerade-cidr: kubelet 向该 IP 段之外的 IP 地址发送的流量将使用 IP 伪装技术,该参数将在未来版本中删除 ?pod-infra-container-image: 仅当容器运行环境设置为 docker 时生效,指定pause镜像root-dir: 设置用于管理 kubelet 文件的根目录(例如挂载卷的相关文件),默认/var/lib/kubelettls-cipher-suites: 服务器端加密算法列表,以逗号分隔,如果不设置,则使用 Go 语言加密包的默认算法列表v: 设置 kubelet 日志级别详细程度的数值
3.2 config 参数
address: kubelet绑定的主机IP地址,默认为0.0.0.0表示绑定全部网络接口allow-privileged: 是否允许以特权模式启动容器。当前默认值为false,已废弃client-ca-file: 基础 ca证书,即 ca.pemcluster-dns: 集群内DNS服务的IP地址,仅当 Pod 设置了 “dnsPolicy=ClusterFirst” 属性时可用cluster-domain: 集群的域名fail-swap-on: 设置为 true 表示如果主机启用了交换分区,kubelet 将无法使用。(默认值为 true)max-pods: kubelet 能运行的 Pod 最大数量。(默认值为 110)feature-gates: 用于 alpha 实验性质的特性开关组,每个开关以 key=value 形式表示pod-manifest-path: 设置包含要运行的static Pod 的文件的路径,或单个静态 Pod 文件的路径anonymous-auth: 设置为 true 表示 kubelet 服务器可以接受匿名请求。enforce-node-allocatable: 包含由 kubelet 强制执行的节点可分配资源级别。可选配置为:‘none’、‘pods’、‘system-reserved’ 和 ‘kube-reserved’kube-reserved-cgroup: 顶层kube cgroup 的名称system-reserved-cgroup: 顶层system cgroup 的名称kube-reserved: kube 组件资源预留system-reserved: 系统组件组件预留eviction-hard: 硬驱逐策略eviction-soft: 软驱逐策略eviction-soft-grace-period: 软驱逐宽限期eviction-max-pod-grace-period: 响应满足软驱逐阈值(soft eviction threshold)而终止 Pod 时使用的最长宽限期(以秒为单位)eviction-minimum-reclaim: 当本节点压力过大时,kubelet 执行软性驱逐操作。此参数设置软性驱逐操作需要回收的资源的最小数量(例如:imagefs.available=2Gi)。
四. 最佳实践
4.1 合理配置驱逐与预留值
详细内容参考:k8s节点资源预留与 pod 驱逐
驱逐:通过--eviction-hard标志预留一些内存后,当节点上的可用内存降至保留值以下时,kubelet 将会对pod进行驱逐。驱逐有软硬两种,而且软驱逐可以细化到持续多久才触发。
预留:可以给系统核心进程、k8s 核心进程配置资源预留,总数-预留数剩下的才是给 pod 分配的量,资源预留建议使用阶梯式,机器配置越高,预留越多
如,对于内存资源:
- 内存少于1GB,则设置255 MiB
- 内存大于4G,设置前4GB内存的25%
- 接下来4GB内存的20%(最多8GB)
- 接下来8GB内存的10%(最多16GB)
- 接下来112GB内存的6%(最高128GB)
- 超过128GB的任何内存的2%
- 在1.12.0之前的版本中,内存小于1GB的节点不需要保留内存
4.2 减少心跳上报频率
设计文档:node-heartbeat
目的:
- 在 Kubernetes 集群中,影响其扩展到更大规模的一个核心问题是如何有效的处理节点的心跳。在一个典型的生产环境中 (non-trival),kubelet 每 10s 汇报一次心跳,每次心跳请求的内容达到 15kb(包含节点上数十计的镜像,和若干的卷信息),这会带来两大问题:
- 心跳请求触发 etcd 中 node 对象的更新,在 10k nodes 的集群中,这些更新将产生近 1GB/min 的 transaction logs(etcd 会记录变更历史);
API Server 很高的 CPU 消耗,node 节点非常庞大,序列化/反序列化开销很大,处理心跳请求的 CPU 开销超过 API Server CPU 时间占用的 80%。
方法:
- 为了解决这个问题,Kubernetes 引入了一个新的 build-in Lease API ,将与心跳密切相关的信息从 node 对象中剥离出来,也就是上图中的 Lease 。原本 kubelet 每 10s 更新一次 node 对象升级为:每 10s 更新一次 Lease 对象,表明该节点的存活状态,Node Controller 根据该 Lease 对象的状态来判断节点是否存活;
-
处于兼容性的考虑,降低为每 60s 更新一次 node 对象,使得 Eviction_ _Manager 等可以继续按照原有的逻辑工作。
-
因为 Lease 对象非常小,因此其更新的代价远小于更新 node 对象。kubernetes 通过这个机制,显著的降低了 API Server 的 CPU 开销,同时也大幅减小了 etcd 中大量的 transaction logs,成功将其规模从 1000 扩展到了几千个节点的规模,该功能在社区 Kubernetes-1.14 中已经默认启用。
具体参考:https://kubernetes.io/docs/concepts/architecture/nodes/#node-topology
4.3 bookmark
设计文档:watch-bookmark
目的:
- watch client 重启后会对所有的资源进行重新 watch,apiserver负载会剧增,可以减少不必要的 watch 事件
- 如果重启前为 resourceVersion v1的资源,重启后发现资源变成了v2,客户端并不会知道,仍然使用 v1,apiserver会将 v2 转到 v1,这里的处理其实是没有必要的
方法:
kubernetes 从v1.15开始 支持 bookmark 机制,bookmark 主要作用是只将特定的事件发送给客户端,从而避免增加 apiserver 的负载。bookmark 的核心思想概括起来就是在 client 与 server 之间保持一个“心跳”,即使队列中无 client 需要感知的更新,reflector 内部的版本号也需要及时的更新。
比如:每个节点上的 kubelet 仅关注 和自己节点相关的 pods,pod storage 队列是有限的(FIFO),当 pods 的队列更新时,旧的变更就会从队列中淘汰,当队列中的更新与某个 kubelet client 无关时,kubelet client watch 的 resourceVersion 仍然保持不变,若此时 kubelet client 重连 apiserver 后,这时候 apiserver 无法判断当前队列的最小值与 kubelet client 之间是否存在需要感知的变更,因此返回 client too old version err 触发 kubelet client 重新 list 所有的数据。
EventType多了一种枚举值:Bookmark
Added EventType = "ADDED"
Modified EventType = "MODIFIED"
Deleted EventType = "DELETED"
Error EventType = "ERROR"
Bookmark EventType = "BOOKMARK"
4.4 hugepages
设计文档: hugepages
目的:
HugePages是Linux内核的一个特性,使用hugepage可以用更大的内存页来取代传统的4K页面。可以提高内存的性能,降低CPU负载,作用详情参考hugepage的优势与使用
对于大内存工作集或者对内存访问延迟很敏感的应用来说,开启hugepages的效果比较显著,如 mysql、java 程序、dpdk等,默认情况下 kubelet启动的 pod 是没有开启hugepages的。
方法:
从 k8s1.8 开始就开始支持hugepage,kubelet中通过--feature-gates=HugePages=true来开启,hugepage 建议谨慎使用,由管理员来分配,因为预分配的大页面会减少节点上可分配的内存量。该节点将像对待其他系统保留一样对待预分配的大页面,可分配 mem 的公式就变成了:
[Allocatable] = [Node Capacity] -
[Kube-Reserved] -
[System-Reserved] -
[Pre-Allocated-HugePages * HugePageSize] -
[Hard-Eviction-Threshold]
如开了 hugepage 的 node 状态为:
apiVersion: v1
kind: Node
metadata:
name: node1
...
status:
capacity:
memory: 10Gi
hugepages-2Mi: 1Gi
allocatable:
memory: 9Gi
hugepages-2Mi: 1Gi
在创建 pod 时可以声明使用这些页内存,
apiVersion: v1
kind: Pod
metadata:
name: example
spec:
containers:
...
volumeMounts:
- mountPath: /hugepages-2Mi
name: hugepage-2Mi
- mountPath: /hugepages-1Gi
name: hugepage-1Gi
resources:
requests:
hugepages-2Mi: 1Gi
hugepages-1Gi: 2Gi
limits:
hugepages-2Mi: 1Gi
hugepages-1Gi: 2Gi
volumes:
- name: hugepage-2Mi
emptyDir:
medium: HugePages-2Mi
- name: hugepage-1Gi
emptyDir:
medium: HugePages-1Gi
4.5 新的健康检查机制
设计文档:[https://github.com/kubernetes/enhancements/blob/master/keps/sig-node/20190221-livenessprobe-holdoff.md]
目的:
健康检查的基础内容参考:K8S 中的健康检查机制
kubelet 中有 health check 相关的逻辑来判断 pod 启动后状态是否正常,如果检查不通过会杀死 pod 重启,直到检查通过,但对于慢启动容器 来说现有的健康检查机制不太好用
慢启动容器:指需要大量时间(一到几分钟)启动的容器。启动缓慢的原因可能有多种:
- 长时间的数据初始化:只有第一次启动会花费很多时间
- 负载很高:每次启动都花费很多时间
- 节点资源不足/过载:即容器启动时间取决于外部因素
这种容器的主要问题在于,在livenessProbe失败之前,应该给它们足够的时间来启动它们。对于这种问题,现有的机制的处理方式为:
- 方法一:livenessProbe中把
延迟初始时间initialDelaySeconds设置的很长,以允许容器启动(即initialDelaySeconds大于平均启动时间)。虽然这样可以确保livenessProbe不会检测失败,但是不知道initialDelaySeconds应该配置为多少,启动时间不是一个固定值。另外,因为livenessProbe在启动过程还没运行,因此pod 得不到反馈,events 看不到内容,如果你initialDelaySeconds是 10 分钟,那这 10 分钟内你不知道在发生什么。 - 方法二:增加livenessProbe的失败次数。即failureThreshold*periodSeconds的乘积足够大,简单粗暴,同时容器在初次成功启动后,就算死锁或以其他方式挂起,livenessProbe也会不断探测
方法二可以解决这个问题,但不够优雅。
因为livenessProbe的设计是为了在 pod 启动成功后进行健康探测,最好前提是 pod 已经启动成功,否则启动阶段的多次失败是没有意义的,因此官方提出了一种新的探针:即startupProbe,startupProbe并不是一种新的数据结构,他完全复用了livenessProbe,只是名字改了下,多了一种概念,关于这个 probe 的提议讨论可以参考issue
使用方式:startup-probes
ports:
- name: liveness-port
containerPort: 8080
hostPort: 8080
livenessProbe:
httpGet:
path: /healthz
port: liveness-port
failureThreshold: 1
periodSeconds: 10
startupProbe:
httpGet:
path: /healthz
port: liveness-port
failureThreshold: 30
periodSeconds: 10
这个配置的含义是:
startupProbe首先检测,该应用程序最多有5分钟(30 * 10 = 300s)完成启动。一旦startupProbe成功一次,livenessProbe将接管,以对后续运行过程中容器死锁提供快速响应。如果startupProbe从未成功,则容器将在300秒后被杀死。
k8s 1.16 才开始支持startupProbe这个特性
Reference
- https://blog.frognew.com/2017/07/kubelet-production-config.html
- https://kubernetes.io/docs/tasks/administer-cluster/reconfigure-kubelet/
- https://kubernetes.io/zh/docs/tasks/administer-cluster/kubelet-config-file/
- https://kubernetes.io/zh/docs/reference/command-line-tools-reference/kubelet/
- https://github.com/kubernetes/kubernetes/blob/master/staging/src/k8s.io/kubelet/config/v1beta1/types.go
- https://github.com/kubernetes/enhancements/blob/master/keps/sig-node/0009-node-heartbeat.md
说点什么
1 评论 在 "kubelet 原理解析:先导片"
[…] kubeletFlags和kubeletConfig的含义可以参考kubelet 先导篇,是 1.10 版本之后 kubelet 对配置的一次重新定义,Flags是机器独占参数,config 是可以共享的参数,可以用于动态更新 kubelet […]