Contents
概述
该项目将被废弃(RETIRED)
Heapster是Kubernetes旗下的一个项目,Heapster是一个收集者,并不是采集
- 1.Heapster可以收集Node节点上的cAdvisor数据:CPU、内存、网络和磁盘
- 2.将每个Node上的cAdvisor的数据进行汇总
- 3.按照kubernetes的资源类型来集合资源,比如Pod、Namespace
- 4.默认的metric数据聚合时间间隔是1分钟。还可以把数据导入到第三方工具ElasticSearch、InfluxDB、Kafka、Graphite
- 5.展示:Grafana或Google Cloud Monitoring
使用场景
- Heapster+InfluxDB+Grafana共同组成了一个流行的监控解决方案
-
Kubernetes原生dashboard的监控图表信息来自heapster
-
在HPA(Horizontal Pod Autoscaling)中也用到了Heapster,HPA将Heapster作为Resource Metrics API,向其获取metric,作为水平扩缩容的监控依据
监控指标
流程:
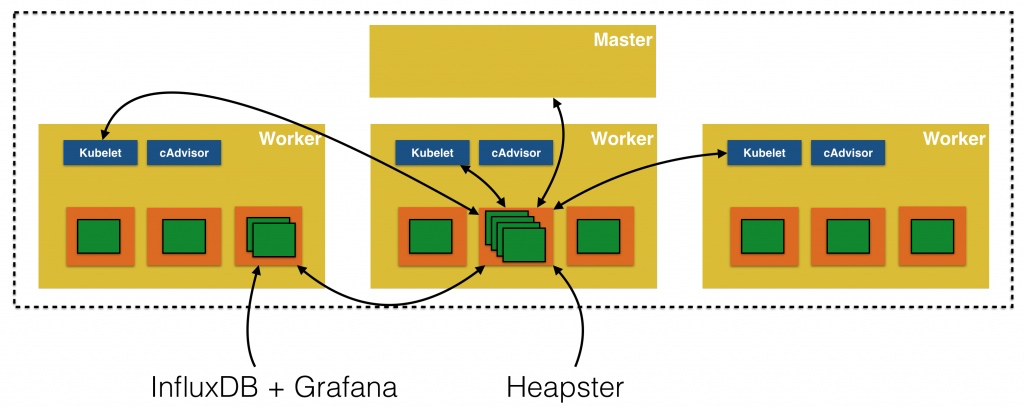
1.Heapster首先从apiserver获取集群中所有Node的信息。
2.通过这些Node上的kubelet获取有用数据,而kubelet本身的数据则是从cAdvisor得到。
3.所有获取到的数据都被推到Heapster配置的后端存储中,并还支持数据的可视化。
部署
docker部署:

k8s中部署:
heapster.yml
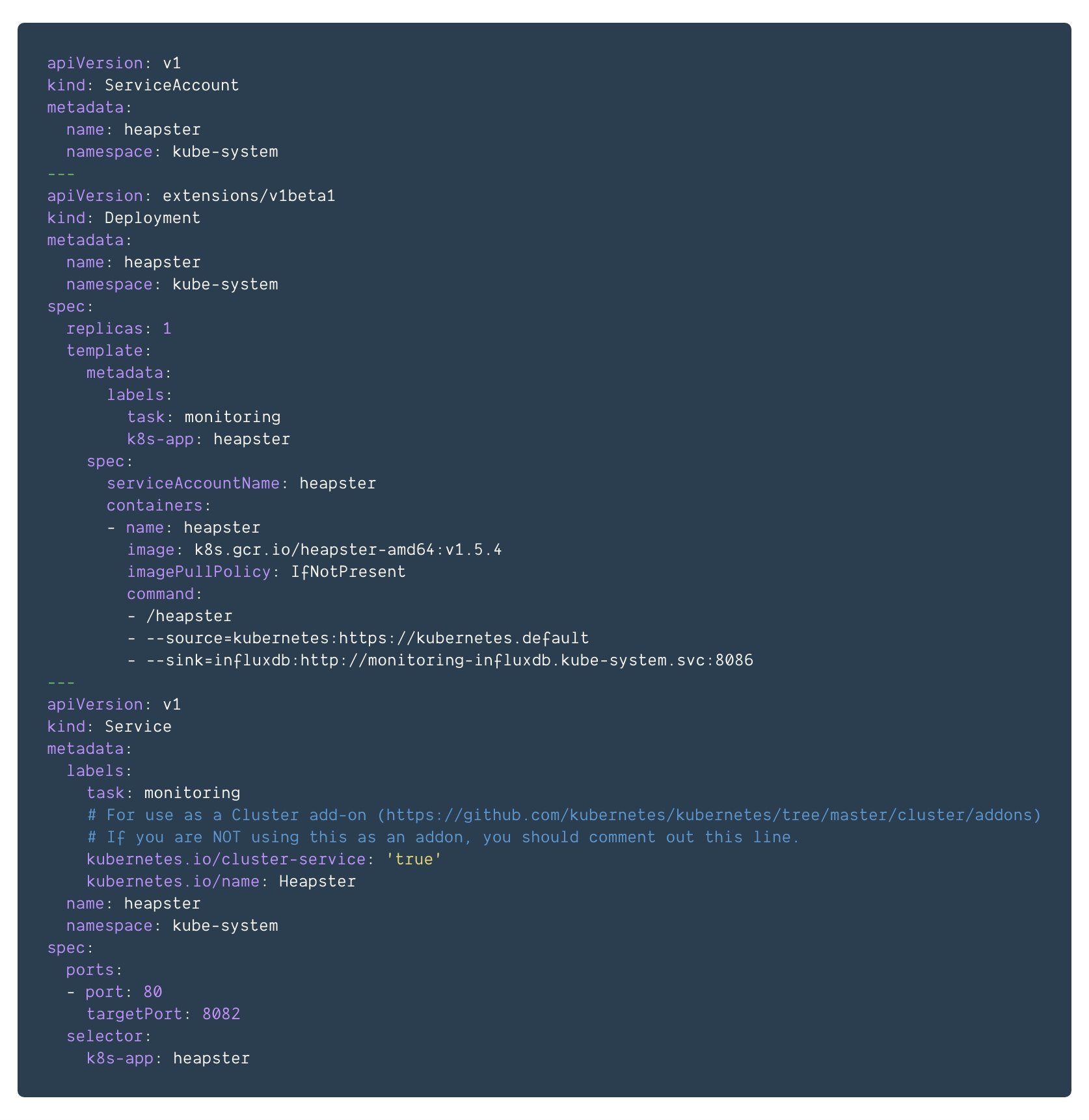
influxdb.yml
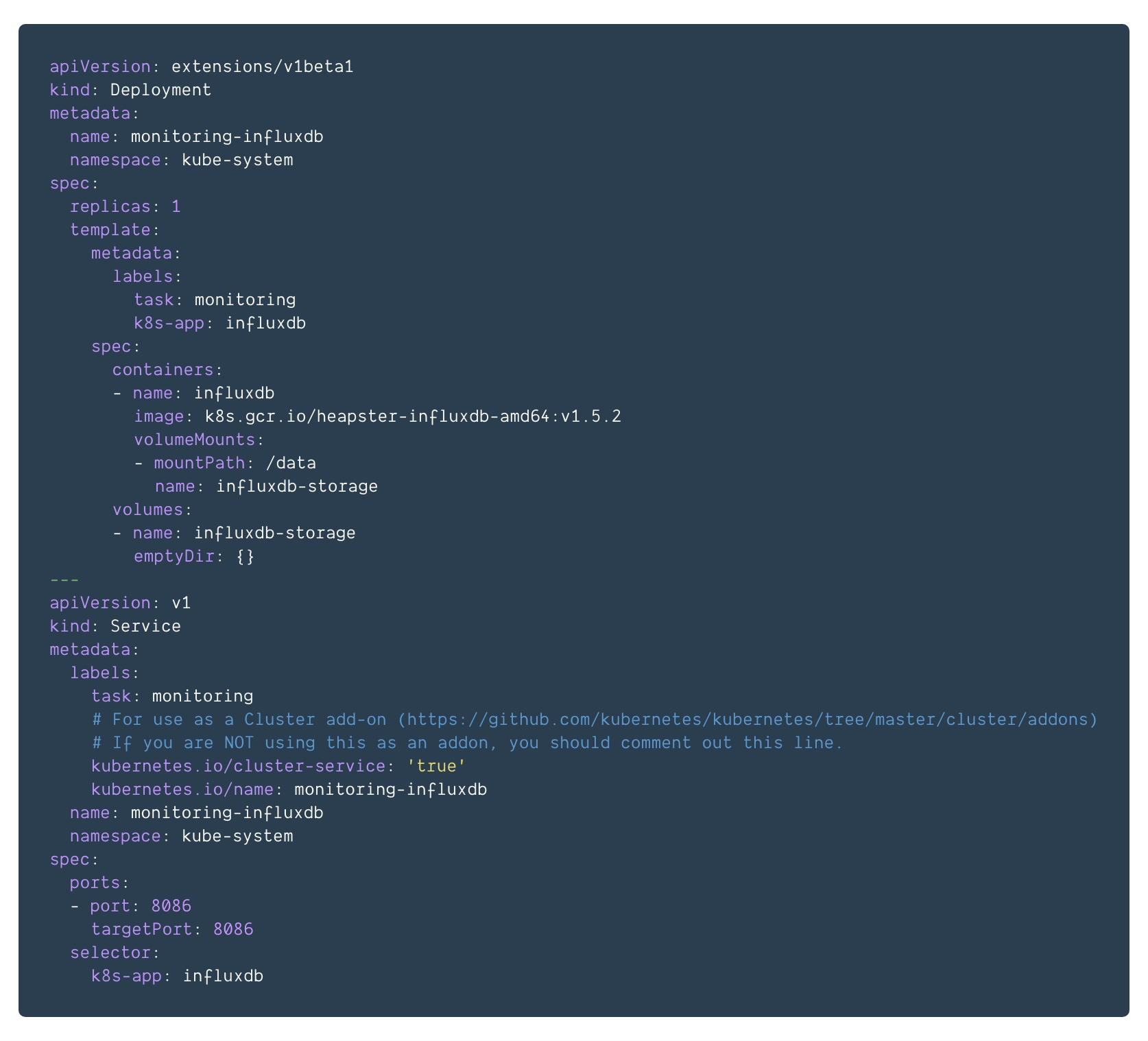
注意修改镜像地址,k8s.gcr.io无法访问的话,修改为内网镜像地址,如替换为registry.cn-hangzhou.aliyuncs.com/google_containers
Heapster的参数
- source: 指定数据获取源,如kube-apiserver
inClusterConfig:
- kubeletPort: 指定kubelet的使用端口,默认10255
- kubeletHttps: 是否使用https去连接kubelets(默认:false)
- apiVersion: 指定K8S的apiversion
- insecure: 是否使用安全证书(默认:false)
- auth: 安全认证
- useServiceAccount: 是否使用K8S的安全令牌
- sink: 指定后端数据存储,这里指定influxdb数据库
Metrics列表
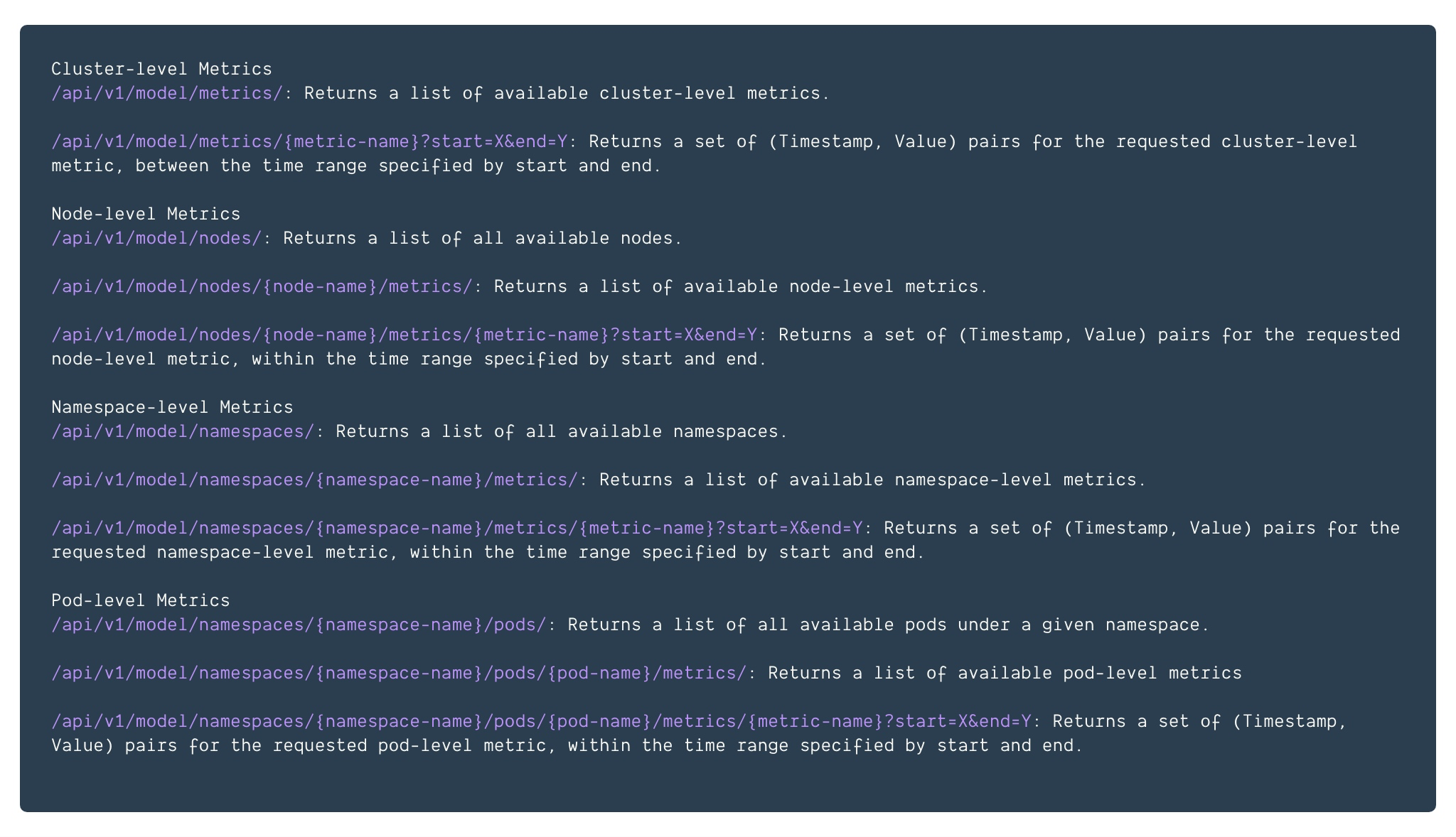
深入解析
架构图:
代码结构(https://github.com/kubernetes-retired/heapster)

heapster主函数(heapster/metrics/heapster.go)
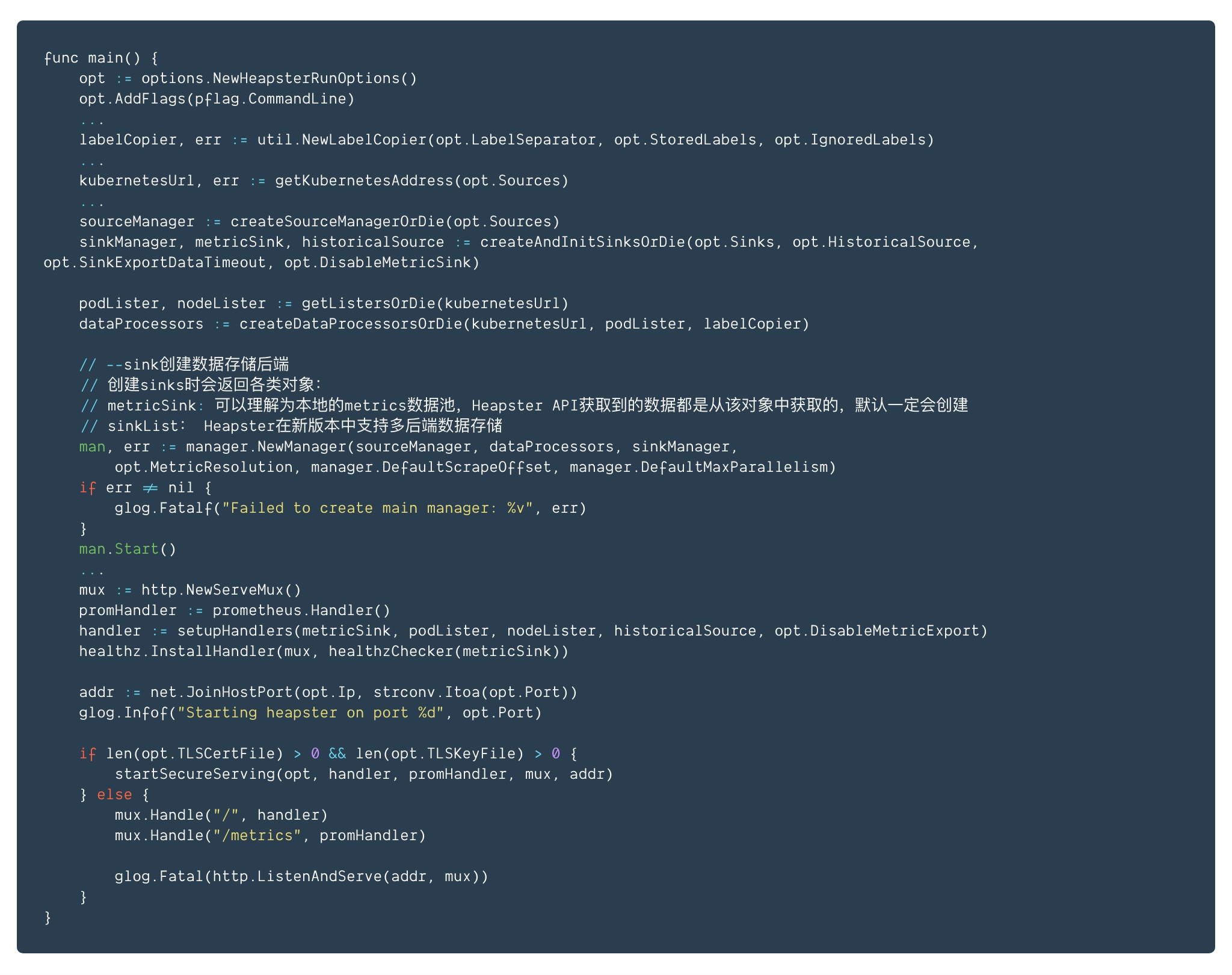
主要流程:
- 创建数据源对象
-
创建后端存储对象list
-
创建处理metrics数据的processors
-
创建manager,并开启数据的获取及export的协程
-
开启Heapster server,并支持各类API
cAdvisor返回的原始数据包含了nodes和containers的相关数据,heapster需要创建各种processor,用于处理成不同类型的数据,比如pod, namespace, cluster,node的聚合,求和平均之类,processor有如下几种:

例如Pod的处理如下:
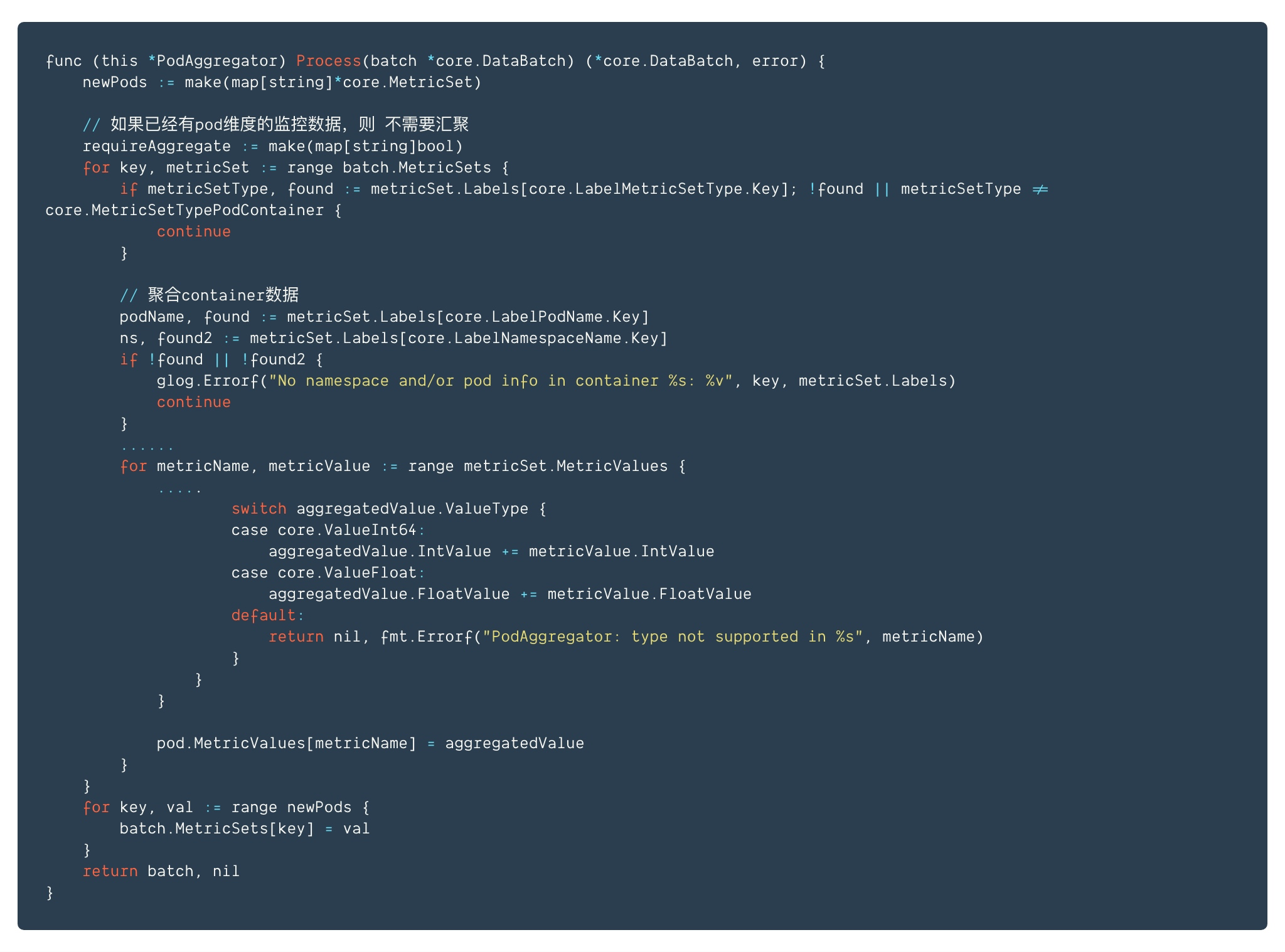
详细解析参考: https://segmentfault.com/a/1190000008863353
现状
heapster已经被官方废弃(k8s 1.11版本中,HPA已经不再从hepaster获取数据)
- CPU内存、HPA指标: 改为metrics-server
- 基础监控:集成到prometheus中,kubelet将metric信息暴露成prometheus需要的格式,使用Prometheus Operator
- 事件监控:集成到https://github.com/heptiolabs/eventrouter
基于Heapster的HPA
本文为容器监控实践系列文章,完整内容见:container-monitor-book
说点什么
欢迎讨论
[…] Heapster […]