Contents
本文主要是读 redhat 出版的《Kubernetes Patterns》的笔记和一些感受,这本书从设计的角度总结了sidecar、Adaptor、controller等概念,为什么这么做,有什么好处。全名是《Kubernetes Patterns: Reusable Elements for Designing Cloud-Native Applications》,即更好的开发云原生应用,书里并不是讲 k8s 的组件架构和设计思想,只是从应用研发的角度解释 pod、sts 等各种资源、设计模式,还没找到中文版,英文 pdf 直接搜索就能找到,就不放链接了。
感觉这本书很适合公司基础架构要做大规模的容器化改造时,做成 ppt 分享给各产品线的研发同学,受众更偏向于业务研发,先分享一次 k8s 的基础知识,再分享一次这个设计模式,以后推动业务改造就方便多了。读之前可以先辅助翻阅《kubernetes 权威指南》或者《kubernetes in action》,
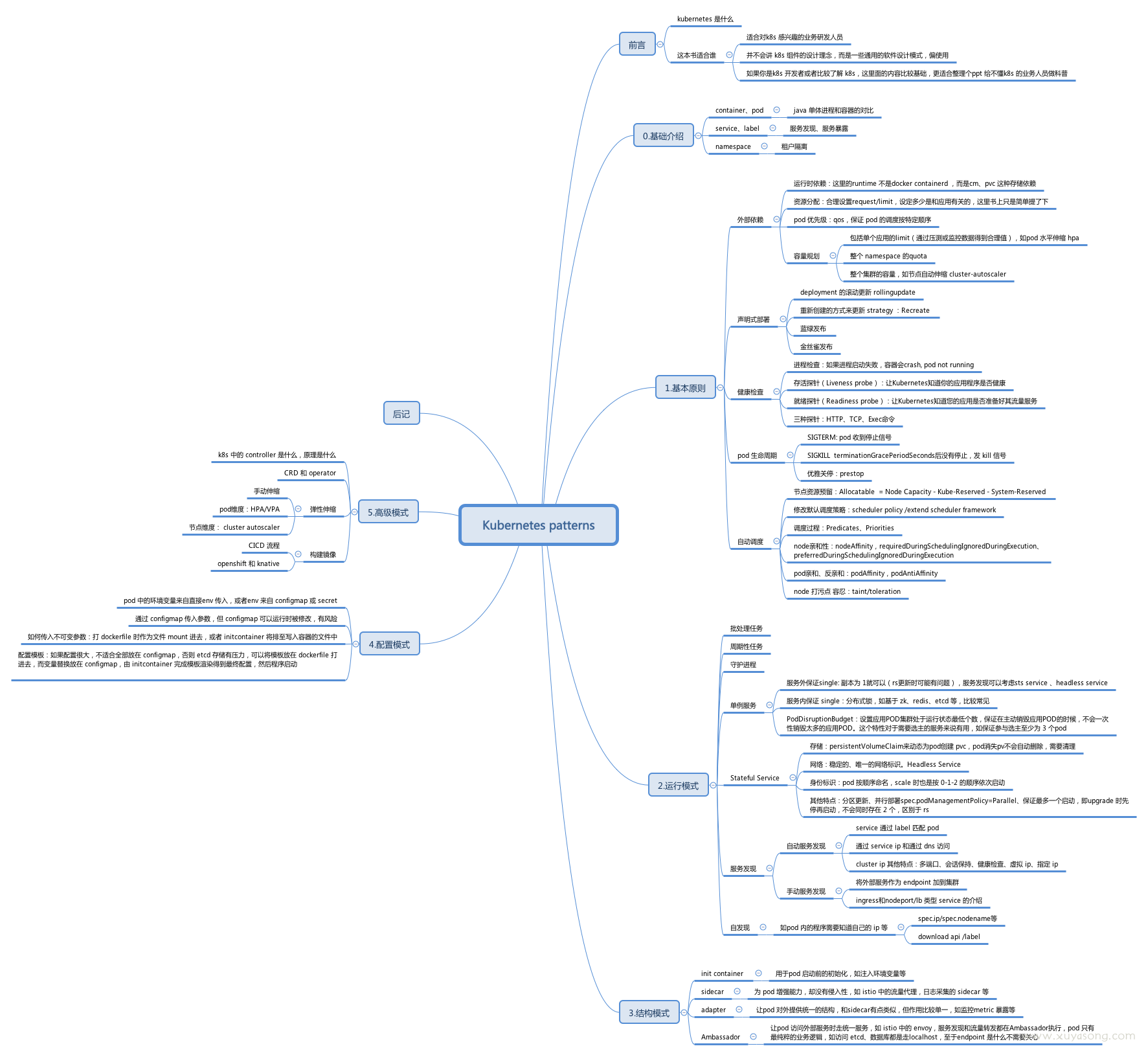
书里很多东西类似 k8s 的官方文档,看完书就画成了思维导图,如下:
容器模式
书中把 java 应用的单机模式和分布式系统中的容器做了对比:
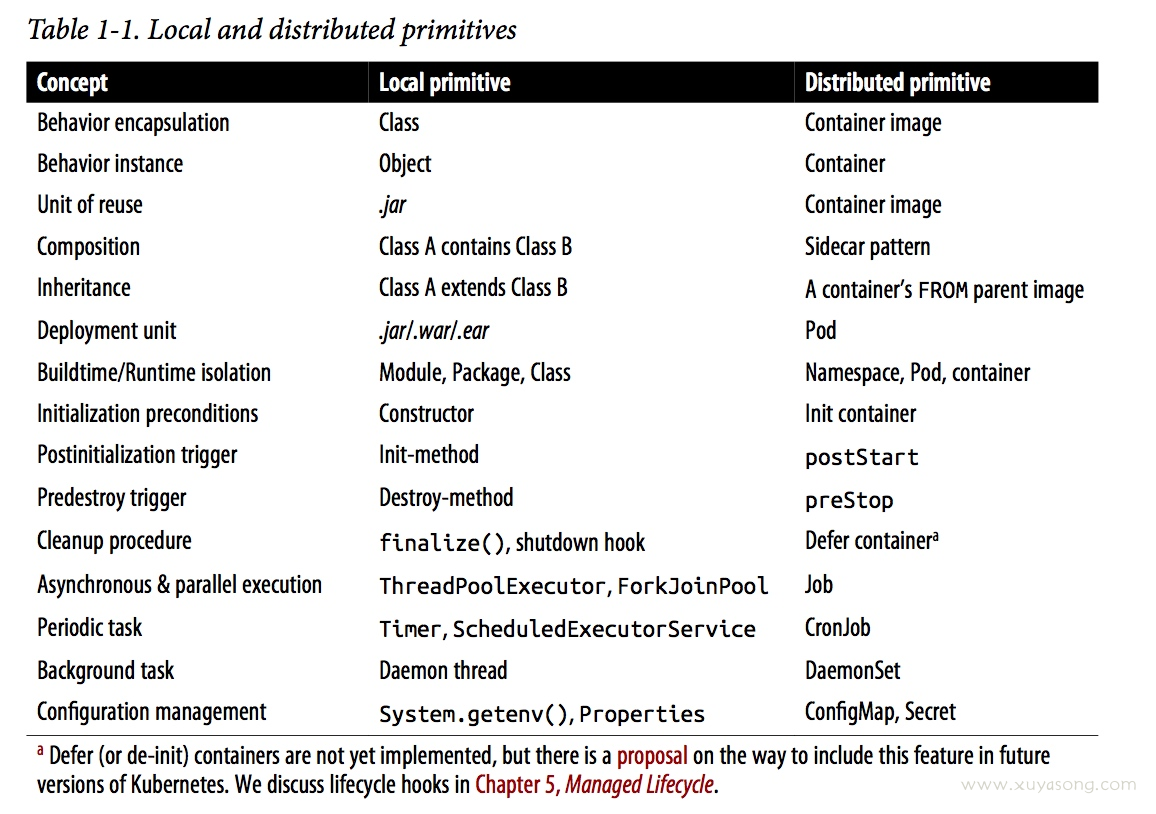
container:
- 容器是(container)是 k8s 应用的基础,完美的符合微服务设计原则。如果和 java 中的 oop做对比,镜像(image)就像类(class),容器就像对象(object),java 中可以通过扩展类实现重用和覆盖,容器也可以使用镜像来扩展其他容器实现重用和覆盖。moudule-package-class 是有包含关系或者运行隔离,namepspace-pod-container 也是类似。
- 容器的基础镜像是可以重用的,即 dockerfile 中的from base image,里面一般包含了大量的排查工具如curl、less、各种 mysql、redis 客户端等,所有的业务容器都引用(基于)这个基础镜像构建,很像你在写代码时的公共库(reusable library)
如果你作为平台方推动过业务的容器化改造,可能经历很多忧伤而又无奈的事情:
- 用户对容器没有概念,dockerfile 写的乱七八糟,没有前台进程,一运行就是 exit,然后还来问你为什么 pod 挂掉了
- 一个容器里面跑了好几个进程,还都是相互依赖的进程,完全把容器当虚机用
- 创建 pod 不限制 cpu 和内存,没有资源分配的概念,机器打挂了一脸懵逼
- 镜像、容器、pod 傻傻分不清楚,每次提问题都得先确认下到底是 镜像问题还是容器问题
- 容器间相互访问,不知道用 svcname 和 svcip,非要固定 pod ip
虽然有些问题现在也有了解决方案,比如pod ip 固定、胖容器、原地升级,但如果能让业务理解容器的设计思想,或者让技术负责人认可容器的模式,也许推动会更顺畅,云原生的体验会更好一点吧。
资源分配和限制
CPU 和内存是程序运行最基础的资源依赖,如果你至少需要2核4G 的资源,那么就给这个 container 设置 request 值,保证你的应用要么启动不了,只有能启动就一定有这么多资源可以独占。
如果你对自己的应用大约需要多少 CPU 和内存没有任何概念,你可以通过压测数据或者线上已有的监控指标来推断单实例的qps、cpu、内存占用,因为这决定了你后续的容量规划,应该要心里有数。离线任务如批处理这种满负载跑的应用除外。
设定完需要的资源,接下来就是设定最高值limit,一般对应了 quota 的概念,即应用最大能使用的资源数量,对于 pod 的 request和 limit 如何设定在 k8s 中并没有最佳实践,因为不同的业务需求不同,插件、核心组件、业务组件的 qos 也不一样,不过设定 request 才助于集群合理调度,如 cpu 密集型和 IO 密集型分配、绑核、判定节点伸缩、最大化地利用资源,为公司”省钱“。
磁盘也是依赖资源,但因为基于磁盘调度在 k8s 中不太成熟,很多公司自己也做了磁盘调度,这里就不展开了。
应用的调度与亲和性
因为 K8S 是容器平台,也就有无数的业务容器同时在运行,这里面就涉及到了调度,调度是一个很复杂的话题,这里只举几个例子和做法
- 有几台机器配置很高,我想让某个应用独占这几台机器。其他人不能调度上去: taint/toleration
- gpu 应用只调度到 gpu 机器,cpu应用调度到非 gpu 机器: node-selector
- 应用 a 和 b 不能在一台机器: pod affinity
- 应用 a 和 b 必须在一台机器: pod affinity
- 一批机器故障了,不能有新应用调度到这台机器: cordon node
- 一批机器故障了,这些机器上的应用全部转移到其他机器: drain node
- 如果机器资源不够了oom 需要杀进程,应该按一定顺序杀,保证核心业务不受影响: pod qos
- 有几个应用很关键,必须保证最高优先级调度: critical-pod/high-priority
- 机器上还有一些非容器进程如监控日志 agent,我需要保证这些进程正常运行: system-reserved
- ….
这只是 k8s 调度能力的基本能力,实际业务中还有很多很复杂的调度策略,调度这一块应该是 k8s 二次开发最多的部分,有点规模的团队就想自己做一些调度方案,满足一些个性化需求。但是 k8s 的 scheduler 的可扩展性很强,如果你觉得不够用,可以用 webhook 或者 scheduler framework开发然后插件式的去集成,不需要直接废掉 scheduler 组件或者上来就改原生代码(造轮子),不然等到大 k8s 版本升级,社区做的比你还好,你还得兼容改造,在 k8s里合理的拓展也许是更好的玩法。
容量规划
合理的调度可以更好地做容量规划,如机器的空置率,机器的实际 cpu 和内存使用率,一般通过监控手段得到趋势图,设置通过预测来判断扩容或采购计划。
容量规划是一个和钱打交道的话题,尤其是上云业务,能最大化利用机器就是为公司省钱,因此集群自动扩缩容,节点的按需创建、销毁是关键能力,这也是上云的优点之一。
pod 的设计模式
这一部分应该是业务研发应该了解的东西,公司之前的一次内部分享就介绍了这几种 patterns
- Init Containers
- sidecar
- adapter
- Ambassador
大多数情况下 sidecar 会和 adapter、Ambassador 有重叠,在看这本书之前,我并没有对这三个概念有所区分,感觉都是差不多的,不过细微之处还是有差别:sidecar 是统称,”边车“就是运行在主容器旁边的容器,只是一种”运行方式“,而 adapter 和 Ambassador 是从作用的角度区分出来的,adapter倾向于 pod 对外暴露统一的接口,如 metric 等,Ambassador 倾向于 pod 访问外部服务时走同一套逻辑,如 istio 的流量转发,localhost 访问数据库等,不过三者目的都是为了让应用只关心自己的业务逻辑。
读取配置
- spec 中声明 env 变量直接传入
- 通过 configmap 传入参数,但 configmap 可以运行时被修改,有风险。
- 如何传入不可变参数:打 dockerfile 时作为文件 mount 进去,或者 initcontainer 将排至写入容器的文件中。
- 配置模板:如果配置很大,不适合全部放在 configmap,否则 etcd 存储有压力,可以将模板放在 dockerfile 打进去,而变量替换放在 configmap,由 initcontainer 完成模板渲染得到最终配置,然后程序启动
controller 模式
书中把 controller 划到了高级模式里面,不过在当前的 k8s 生态里,不会开发 operator 应该算是跟不上发展的脚步了,k8s 的 controller 设计有很多东西可以借鉴,如果你之前的接口不是声明式的,改造成 controller 的方式会让你有很多收获。
拓展 CRD 也有很多开发工具,如operator-sdk和 kubebuilder,不需要刀耕火种地去定义新的资源、watch 这些资源的add、update事件,一键就生成 operator 需要的所有内容,你只需要关心如何实现自己的 reconcile loop
弹性伸缩:HPA/VPA/cluster autoscaler
弹性伸缩主要解决的问题是容量规划与实际负载的矛盾,场景有很多,主要包括
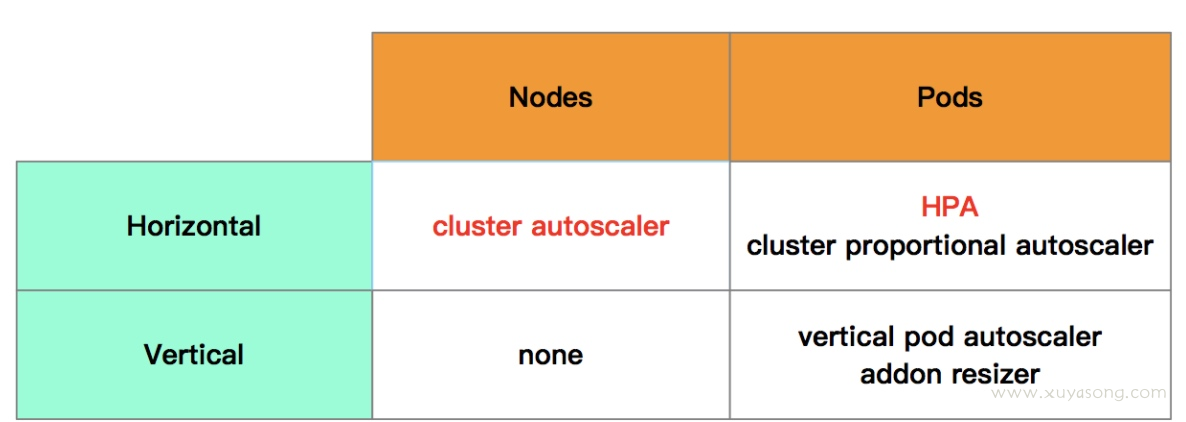
- HPA: Pod 水平伸缩的组件,是所有伸缩组件中历史最悠久最成熟的,可以基于原生 的cpu 内存指标,也可以基于 prometheus 的自定义指标,是根据 pod 的cpu 和内存,水平扩展 pod 个数
- VPA: Pod 垂直伸缩组件,还处在beta阶段,根据 Pod 的资源利用率来 pod 的Request值
- cluster autoscaler: 节点水平伸缩的组件,GA阶段,根据一些状态来扩、缩节点,如资源不足 pod 处于 pending 时扩节点,node 的资源占用率过低就删节点。
- addon-resizer:根据集群中节点的数目纵向调整 pod 的Request的
- cluster-proportional-autoscaler:根据集群的节点数目水平调整 Pod 数目
- cronhpa: 定时的 hpa 组件,指定的时间周期进行 HPA 操作
说点什么
1 评论 在 "K8S 中的设计模式- 读《Kubernetes Patterns》"
> 你觉得不够用,可以用 webhook 或者 scheduler framework开发然后插件式的去集成,不需要直接废掉 scheduler 组件或者上来就改原生代码(造轮子),不然等到大 k8s 版本升级,社区做的比你还好,你还得兼容改造,在 k8s里合理的拓展也许是更好的玩法。
这个真的是挺痛的。