Contents
概述
在传统单体应用单机部署的情况下,可以使用Java并发处理相关的API(如ReentrantLock或Synchronized)进行互斥控制。在单机环境中,Java中提供了很多并发处理相关的API。但是,随着业务发展的需要,原单体单机部署的系统被演化成分布式集群系统后,由于分布式系统多线程、多进程并且分布在不同机器上,这将使原单机部署情况下的并发控制锁策略失效,单纯的Java API并不能提供分布式锁的能力。为了解决这个问题就需要一种跨JVM的互斥机制来控制共享资源的访问,这就是分布式锁要解决的问题!
锁是在执行多线程时用于强行限制资源访问的同步机制,在单机系统上,可以使用Java并发处理相关的API(如ReentrantLock或Synchronized)进行互斥控制。而在分布式系统场景下,实例会运行在多台机器上,为了使多进程(多实例上)对共享资源的读写同步,保证数据的最终一致性,引入了分布式锁。
分布式锁应具备以下特点:
- 互斥性:在任意时刻,只有一个客户端(进程)能持有锁
- 安全性:避免死锁情况,当一个客户端在持有锁期间内,由于意外崩溃而导致锁未能主动解锁,其持有的锁也能够被正确释放,并保证后续其它客户端也能加锁
- 可用性:分布式锁需要有一定的高可用能力,当提供锁的服务节点故障(宕机)时不影响服务运行,避免单点风险,如Redis的集群模式、哨兵模式,ETCD/zookeeper的集群选主能力等保证HA,保证自身持有的数据与故障节点一致。
- 对称性:对同一个锁,加锁和解锁必须是同一个进程,即不能把其他进程持有的锁给释放了,这又称为锁的可重入性。
分布式锁常见实现方式:
- 通过数据库方式实现:采用乐观锁、悲观锁或者基于主键唯一约束实现
- 基于分布式缓存实现的锁服务: Redis 和基于 Redis 的 RedLock(Redisson提供了参考实现)
- 基于分布式一致性算法实现的锁服务:ZooKeeper、Chubby(google闭源实现)和 Etcd
网上常见的是基于Redis和ZooKeeper的实现,基于数据库的因为实现繁琐且性能较差,不想维护第三方中间件的可以考虑。本文主要描述基于 ETCD 的实现,etcd3 的client也给出了新的 api,使用上更为简单
基于 Redis 的实现
既然是锁,核心操作无外乎加锁、解锁。
Redis的加锁操作:
SET lock_name my_random_value NX PX 30000
- lock_name,锁的名称,对于 Redis 而言,lock_name 就是 Key-Value 中的 Key,具有唯一性。
- random_value,由客户端生成的一个随机字符串,它要保证在足够长的一段时间内,且在所有客户端的所有获取锁的请求中都是唯一的,用于唯一标识锁的持有者。
- NX 只有当 lock_name(key) 不存在的时候才能 SET 成功,从而保证只有一个客户端能获得锁,而其它客户端在锁被释放之前都无法获得锁。
- PX 30000 表示这个锁节点有一个 30 秒的自动过期时间(目的是为了防止持有锁的客户端故障后,无法主动释放锁而导致死锁,因此要求锁的持有者必须在过期时间之内执行完相关操作并释放锁)。
Redis的解锁操作:
del lock_name
- 在加锁时为锁设置过期时间,当过期时间到达,Redis 会自动删除对应的 Key-Value,从而避免死锁。注意,这个过期时间需要结合具体业务综合评估设置,以保证锁的持有者能够在过期时间之内执行完相关操作并释放锁。
- 正常执行完毕,未到达锁过期时间,通过del lock_name主动释放锁。
基于 ETCD的分布式锁
机制
etcd 支持以下功能,正是依赖这些功能来实现分布式锁的:
- Lease 机制:即租约机制(TTL,Time To Live),Etcd 可以为存储的 KV 对设置租约,当租约到期,KV 将失效删除;同时也支持续约,即 KeepAlive。
- Revision 机制:每个 key 带有一个 Revision 属性值,etcd 每进行一次事务对应的全局 Revision 值都会加一,因此每个 key 对应的 Revision 属性值都是全局唯一的。通过比较 Revision 的大小就可以知道进行写操作的顺序。
- 在实现分布式锁时,多个程序同时抢锁,根据 Revision 值大小依次获得锁,可以避免 “羊群效应” (也称 “惊群效应”),实现公平锁。
- Prefix 机制:即前缀机制,也称目录机制。可以根据前缀(目录)获取该目录下所有的 key 及对应的属性(包括 key, value 以及 revision 等)。
- Watch 机制:即监听机制,Watch 机制支持 Watch 某个固定的 key,也支持 Watch 一个目录(前缀机制),当被 Watch 的 key 或目录发生变化,客户端将收到通知。
过程
实现过程:
- 步骤 1: 准备
客户端连接 Etcd,以 /lock/mylock 为前缀创建全局唯一的 key,假设第一个客户端对应的 key=”/lock/mylock/UUID1″,第二个为 key=”/lock/mylock/UUID2″;客户端分别为自己的 key 创建租约 – Lease,租约的长度根据业务耗时确定,假设为 15s;
- 步骤 2: 创建定时任务作为租约的“心跳”
当一个客户端持有锁期间,其它客户端只能等待,为了避免等待期间租约失效,客户端需创建一个定时任务作为“心跳”进行续约。此外,如果持有锁期间客户端崩溃,心跳停止,key 将因租约到期而被删除,从而锁释放,避免死锁。
- 步骤 3: 客户端将自己全局唯一的 key 写入 Etcd
进行 put 操作,将步骤 1 中创建的 key 绑定租约写入 Etcd,根据 Etcd 的 Revision 机制,假设两个客户端 put 操作返回的 Revision 分别为 1、2,客户端需记录 Revision 用以接下来判断自己是否获得锁。
- 步骤 4: 客户端判断是否获得锁
客户端以前缀 /lock/mylock 读取 keyValue 列表(keyValue 中带有 key 对应的 Revision),判断自己 key 的 Revision 是否为当前列表中最小的,如果是则认为获得锁;否则监听列表中前一个 Revision 比自己小的 key 的删除事件,一旦监听到删除事件或者因租约失效而删除的事件,则自己获得锁。
- 步骤 5: 执行业务
获得锁后,操作共享资源,执行业务代码。
- 步骤 6: 释放锁
完成业务流程后,删除对应的key释放锁。
实现
自带的 etcdctl 可以模拟锁的使用:
// 第一个终端
$ ./etcdctl lock mutex1
mutex1/326963a02758b52d
// 第二终端
$ ./etcdctl lock mutex1
// 当第一个终端结束了,第二个终端会显示
mutex1/326963a02758b531
在etcd的clientv3包中,实现了分布式锁。使用起来和mutex是类似的,为了了解其中的工作机制,这里简要的做一下总结。
etcd分布式锁的实现在go.etcd.io/etcd/clientv3/concurrency包中,主要提供了以下几个方法:
* func NewMutex(s *Session, pfx string) *Mutex, 用来新建一个mutex
* func (m *Mutex) Lock(ctx context.Context) error,它会阻塞直到拿到了锁,并且支持通过context来取消获取锁。
* func (m *Mutex) Unlock(ctx context.Context) error,解锁
因此在使用etcd提供的分布式锁式非常简单,通常就是实例化一个mutex,然后尝试抢占锁,之后进行业务处理,最后解锁即可。
demo:
package main
import (
"context"
"fmt"
"github.com/coreos/etcd/clientv3"
"github.com/coreos/etcd/clientv3/concurrency"
"log"
"os"
"os/signal"
"time"
)
func main() {
c := make(chan os.Signal)
signal.Notify(c)
cli, err := clientv3.New(clientv3.Config{
Endpoints: []string{"localhost:2379"},
DialTimeout: 5 * time.Second,
})
if err != nil {
log.Fatal(err)
}
defer cli.Close()
lockKey := "/lock"
go func () {
session, err := concurrency.NewSession(cli)
if err != nil {
log.Fatal(err)
}
m := concurrency.NewMutex(session, lockKey)
if err := m.Lock(context.TODO()); err != nil {
log.Fatal("go1 get mutex failed " + err.Error())
}
fmt.Printf("go1 get mutex sucess\n")
fmt.Println(m)
time.Sleep(time.Duration(10) * time.Second)
m.Unlock(context.TODO())
fmt.Printf("go1 release lock\n")
}()
go func() {
time.Sleep(time.Duration(2) * time.Second)
session, err := concurrency.NewSession(cli)
if err != nil {
log.Fatal(err)
}
m := concurrency.NewMutex(session, lockKey)
if err := m.Lock(context.TODO()); err != nil {
log.Fatal("go2 get mutex failed " + err.Error())
}
fmt.Printf("go2 get mutex sucess\n")
fmt.Println(m)
time.Sleep(time.Duration(2) * time.Second)
m.Unlock(context.TODO())
fmt.Printf("go2 release lock\n")
}()
<-c
}
原理
Lock()函数的实现很简单:
// Lock locks the mutex with a cancelable context. If the context is canceled
// while trying to acquire the lock, the mutex tries to clean its stale lock entry.
func (m *Mutex) Lock(ctx context.Context) error {
s := m.s
client := m.s.Client()
m.myKey = fmt.Sprintf("%s%x", m.pfx, s.Lease())
cmp := v3.Compare(v3.CreateRevision(m.myKey), "=", 0)
// put self in lock waiters via myKey; oldest waiter holds lock
put := v3.OpPut(m.myKey, "", v3.WithLease(s.Lease()))
// reuse key in case this session already holds the lock
get := v3.OpGet(m.myKey)
// fetch current holder to complete uncontended path with only one RPC
getOwner := v3.OpGet(m.pfx, v3.WithFirstCreate()...)
resp, err := client.Txn(ctx).If(cmp).Then(put, getOwner).Else(get, getOwner).Commit()
if err != nil {
return err
}
m.myRev = resp.Header.Revision
if !resp.Succeeded {
m.myRev = resp.Responses[0].GetResponseRange().Kvs[0].CreateRevision
}
// if no key on prefix / the minimum rev is key, already hold the lock
ownerKey := resp.Responses[1].GetResponseRange().Kvs
if len(ownerKey) == 0 || ownerKey[0].CreateRevision == m.myRev {
m.hdr = resp.Header
return nil
}
// wait for deletion revisions prior to myKey
hdr, werr := waitDeletes(ctx, client, m.pfx, m.myRev-1)
// release lock key if wait failed
if werr != nil {
m.Unlock(client.Ctx())
} else {
m.hdr = hdr
}
return werr
}
首先通过一个事务来尝试加锁,这个事务主要包含了4个操作: cmp、put、get、getOwner。需要注意的是,key是由pfx和Lease()组成的。
- cmp: 比较加锁的key的修订版本是否是0。如果是0就代表这个锁不存在。
- put: 向加锁的key中存储一个空值,这个操作就是一个加锁的操作,但是这把锁是有超时时间的,超时的时间是session的默认时长。超时是为了防止锁没有被正常释放导致死锁。
- get: get就是通过key来查询
- getOwner: 注意这里是用m.pfx来查询的,并且带了查询参数WithFirstCreate()。使用pfx来查询是因为其他的session也会用同样的pfx来尝试加锁,并且因为每个LeaseID都不同,所以第一次肯定会put成功。但是只有最早使用这个pfx的session才是持有锁的,所以这个getOwner的含义就是这样的。
接下来才是通过判断来检查是否持有锁
m.myRev = resp.Header.Revision
if !resp.Succeeded {
m.myRev = resp.Responses[0].GetResponseRange().Kvs[0].CreateRevision
}
// if no key on prefix / the minimum rev is key, already hold the lock
ownerKey := resp.Responses[1].GetResponseRange().Kvs
if len(ownerKey) == 0 || ownerKey[0].CreateRevision == m.myRev {
m.hdr = resp.Header
return nil
}
m.myRev是当前的版本号,resp.Succeeded是cmp为true时值为true,否则是false。这里的判断表明当同一个session非第一次尝试加锁,当前的版本号应该取这个key的最新的版本号。
下面是取得锁的持有者的key。如果当前没有人持有这把锁,那么默认当前会话获得了锁。或者锁持有者的版本号和当前的版本号一致, 那么当前的会话就是锁的持有者。
// wait for deletion revisions prior to myKey
hdr, werr := waitDeletes(ctx, client, m.pfx, m.myRev-1)
// release lock key if wait failed
if werr != nil {
m.Unlock(client.Ctx())
} else {
m.hdr = hdr
}
上面这段代码就很好理解了,因为走到这里说明没有获取到锁,那么这里等待锁的删除。
waitDeletes方法的实现也很简单,但是需要注意的是,这里的getOpts只会获取比当前会话版本号更低的key,然后去监控最新的key的删除。等这个key删除了,自己也就拿到锁了。
这种分布式锁的实现和我一开始的预想是不同的。它不存在锁的竞争,不存在重复的尝试加锁的操作。而是通过使用统一的前缀pfx来put,然后根据各自的版本号来排队获取锁。效率非常的高。避免了惊群效应
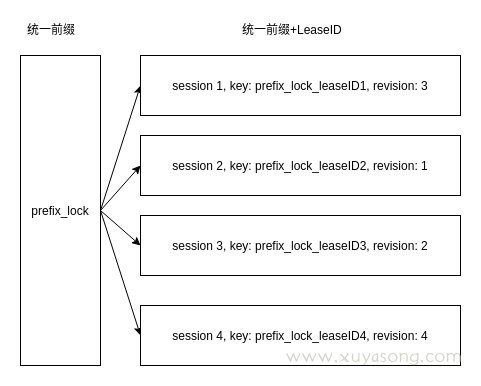
如图所示,共有4个session来加锁,那么根据revision来排队,获取锁的顺序为session2 -> session3 -> session1 -> session4。
这里面需要注意一个惊群效应,每一个client在锁住/lock这个path的时候,实际都已经插入了自己的数据,类似/lock/LEASE_ID,并且返回了各自的index(就是raft算法里面的日志索引),而只有最小的才算是拿到了锁,其他的client需要watch等待。例如client1拿到了锁,client2和client3在等待,而client2拿到的index比client3的更小,那么对于client1删除锁之后,client3其实并不关心,并不需要去watch。所以综上,等待的节点只需要watch比自己index小并且差距最小的节点删除事件即可。
基于 ETCD的选主
机制
etcd有多种使用场景,Master选举是其中一种。说起Master选举,过去常常使用zookeeper,通过创建EPHEMERAL_SEQUENTIAL节点(临时有序节点),我们选择序号最小的节点作为Master,逻辑直观,实现简单是其优势,但是要实现一个高健壮性的选举并不简单,同时zookeeper繁杂的扩缩容机制也是沉重的负担。
master 选举根本上也是抢锁,与zookeeper直观选举逻辑相比,etcd的选举则需要在我们熟悉它的一系列基本概念后,调动我们充分的想象力:
- 1、MVCC,key存在版本属性,没被创建时版本号为0;
-
2、CAS操作,结合MVCC,可以实现竞选逻辑,if(version == 0) set(key,value),通过原子操作,确保只有一台机器能set成功;
-
3、Lease租约,可以对key绑定一个租约,租约到期时没预约,这个key就会被回收;
-
4、Watch监听,监听key的变化事件,如果key被删除,则重新发起竞选。
至此,etcd选举的逻辑大体清晰了,但这一系列操作与zookeeper相比复杂很多,有没有已经封装好的库可以直接拿来用?etcd clientv3 concurrency中有对选举及分布式锁的封装。后面进一步发现,etcdctl v3里已经有master选举的实现了,下面针对这部分代码进行简单注释,在最后参考这部分代码实现自己的选举逻辑。
实现
官方示例:https://github.com/etcd-io/etcd/blob/master/clientv3/concurrency/example_election_test.go
如crontab 示例:
package main
import (
"context"
"fmt"
"go.etcd.io/etcd/clientv3"
"go.etcd.io/etcd/clientv3/concurrency"
"log"
"time"
)
const prefix = "/election-demo"
const prop = "local"
func main() {
endpoints := []string{"szth-cce-devops00.szth.baidu.com:8379"}
cli, err := clientv3.New(clientv3.Config{Endpoints: endpoints})
if err != nil {
log.Fatal(err)
}
defer cli.Close()
campaign(cli, prefix, prop)
}
func campaign(c *clientv3.Client, election string, prop string) {
for {
// 租约到期时间:5s
s, err := concurrency.NewSession(c, concurrency.WithTTL(5))
if err != nil {
fmt.Println(err)
continue
}
e := concurrency.NewElection(s, election)
ctx := context.TODO()
log.Println("开始竞选")
err = e.Campaign(ctx, prop)
if err != nil {
log.Println("竞选 leader失败,继续")
switch {
case err == context.Canceled:
return
default:
continue
}
}
log.Println("获得leader")
if err := doCrontab(); err != nil {
log.Println("调用主方法失败,辞去leader,重新竞选")
_ = e.Resign(ctx)
continue
}
return
}
}
func doCrontab() error {
for {
fmt.Println("doCrontab")
time.Sleep(time.Second * 4)
//return fmt.Errorf("sss")
}
}
原理
/*
* 发起竞选
* 未当选leader前,会一直阻塞在Campaign调用
* 当选leader后,等待SIGINT、SIGTERM或session过期而退出
* https://github.com/etcd-io/etcd/blob/master/etcdctl/ctlv3/command/elect_command.go
*/
func campaign(c *clientv3.Client, election string, prop string) error {
//NewSession函数中创建了一个lease,默认是60s TTL,并会调用KeepAlive,永久为这个lease自动续约(2/3生命周期的时候执行续约操作)
s, err := concurrency.NewSession(c)
if err != nil {
return err
}
e := concurrency.NewElection(s, election)
ctx, cancel := context.WithCancel(context.TODO())
donec := make(chan struct{})
sigc := make(chan os.Signal, 1)
signal.Notify(sigc, syscall.SIGINT, syscall.SIGTERM)
go func() {
<-sigc
cancel()
close(donec)
}()
//竞选逻辑,将展开分析
if err = e.Campaign(ctx, prop); err != nil {
return err
}
// print key since elected
resp, err := c.Get(ctx, e.Key())
if err != nil {
return err
}
display.Get(*resp)
select {
case <-donec:
case <-s.Done():
return errors.New("elect: session expired")
}
return e.Resign(context.TODO())
}
/*
* 类似于zookeeper的临时有序节点,etcd的选举也是在相应的prefix path下面创建key,该key绑定了lease并根据lease id进行命名,
* key创建后就有revision号,这样使得在prefix path下的key也都是按revision有序
* https://github.com/etcd-io/etcd/blob/master/clientv3/concurrency/election.go
*/
func (e *Election) Campaign(ctx context.Context, val string) error {
s := e.session
client := e.session.Client()
//真正创建的key名为:prefix + lease id
k := fmt.Sprintf("%s%x", e.keyPrefix, s.Lease())
//Txn:transaction,依靠Txn进行创建key的CAS操作,当key不存在时才会成功创建
txn := client.Txn(ctx).If(v3.Compare(v3.CreateRevision(k), "=", 0))
txn = txn.Then(v3.OpPut(k, val, v3.WithLease(s.Lease())))
txn = txn.Else(v3.OpGet(k))
resp, err := txn.Commit()
if err != nil {
return err
}
e.leaderKey, e.leaderRev, e.leaderSession = k, resp.Header.Revision, s
//如果key已存在,则创建失败;
//当key的value与当前value不等时,如果自己为leader,则不用重新执行选举直接设置value;
//否则报错。
if !resp.Succeeded {
kv := resp.Responses[0].GetResponseRange().Kvs[0]
e.leaderRev = kv.CreateRevision
if string(kv.Value) != val {
if err = e.Proclaim(ctx, val); err != nil {
e.Resign(ctx)
return err
}
}
}
//一直阻塞,直到确认自己的create revision为当前path中最小,从而确认自己当选为leader
_, err = waitDeletes(ctx, client, e.keyPrefix, e.leaderRev-1)
if err != nil {
// clean up in case of context cancel
select {
case <-ctx.Done():
e.Resign(client.Ctx())
default:
e.leaderSession = nil
}
return err
}
e.hdr = resp.Header
return nil
}
锁基础:
https://tech.meituan.com/2018/11/15/java-lock.html
Reference
- https://godoc.org/go.etcd.io/etcd/clientv3/concurrency#Mutex.Lock
- 三种分布式锁实现:https://juejin.im/post/5bbb0d8df265da0abd3533a5
- http://harlon.org/2018/04/14/distributedsystemlock/
- http://wuwenliang.net/2019/07/23/%E5%86%8D%E8%B0%88%E5%88%86%E5%B8%83%E5%BC%8F%E9%94%81%E4%B9%8B%E5%89%96%E6%9E%90Redis%E5%AE%9E%E7%8E%B0/
- https://www.myway5.com/index.php/2019/10/09/etcd%E5%88%86%E5%B8%83%E5%BC%8F%E9%94%81%E7%9A%84%E5%AE%9E%E7%8E%B0%E6%96%B9%E5%BC%8F/
- https://github.com/jinhailang/blog/issues/47
- https://cloud.tencent.com/developer/article/1458456
- https://github.com/etcd-io/etcd/blob/master/clientv3/concurrency/example_election_test.go
- https://tech.meituan.com/2018/11/15/java-lock.html
说点什么
2 评论 在 "基于 etcd 实现分布式锁"
[…] 我们是用etcd client做应用的选主操作,可以看下这篇 […]
[…] 在 k8s 中,kube-scheduler 和 kube-controller-manager 两个组件是有 leader 选举的,这个选举机制是 k8s 对于这两个组件的高可用保障,虽然 k8s 的存储使用了 etcd,但并没有使用 etcd 来实现选主,而是对 endpoint 这个资源做抢占,谁想抢到并将自己的信息写入 endpoint的 annotation 中,谁就获得了主。因为需要写一个 k8s 的插件,同样需要选主逻辑,因此复用了 k8s 中的这个方法,即kubernetes 的 tools/leaderelection包。本文主要介绍下选主逻辑的实现,基于 etcd client 实现选主可以看另一篇文章 […]