基于 RED方法 和 USE 方法 对以下四类指标进行分析:
- cadvisor 指标分析
- node-exporter 指标分析
- etcd 指标分析
- apiserver 指标分析
cadvisor 指标分析
在Kubernetes中,cAdvisor嵌入到kubelet中,本文使用 USE 方法对容器的指标进行分析。
USE方法代表
- 利用率
- 饱和度
- 错误
cAdvisor提供的“容器”指标最终是底层Linux cgroup提供的。就像节点指标一样,很多很详细。但是我们一般对CPU,内存,网络和磁盘感兴趣
CPU
利用率
对于CPU利用率,Kubernetes仅为我们提供了每个容器的三个指标
- container_cpu_user_seconds_total —“用户”时间的总数(即不在内核中花费的时间)
- container_cpu_system_seconds_total —“系统”时间的总数(即在内核中花费的时间)
- container_cpu_usage_seconds_total—以上总和
所有这些指标都是couter类型,需要对其rate算出使用率吗.
下面的查询展示每个容器正在使用的CPU:
sum(
rate(container_cpu_usage_seconds_total [5m]))
by(container_name)
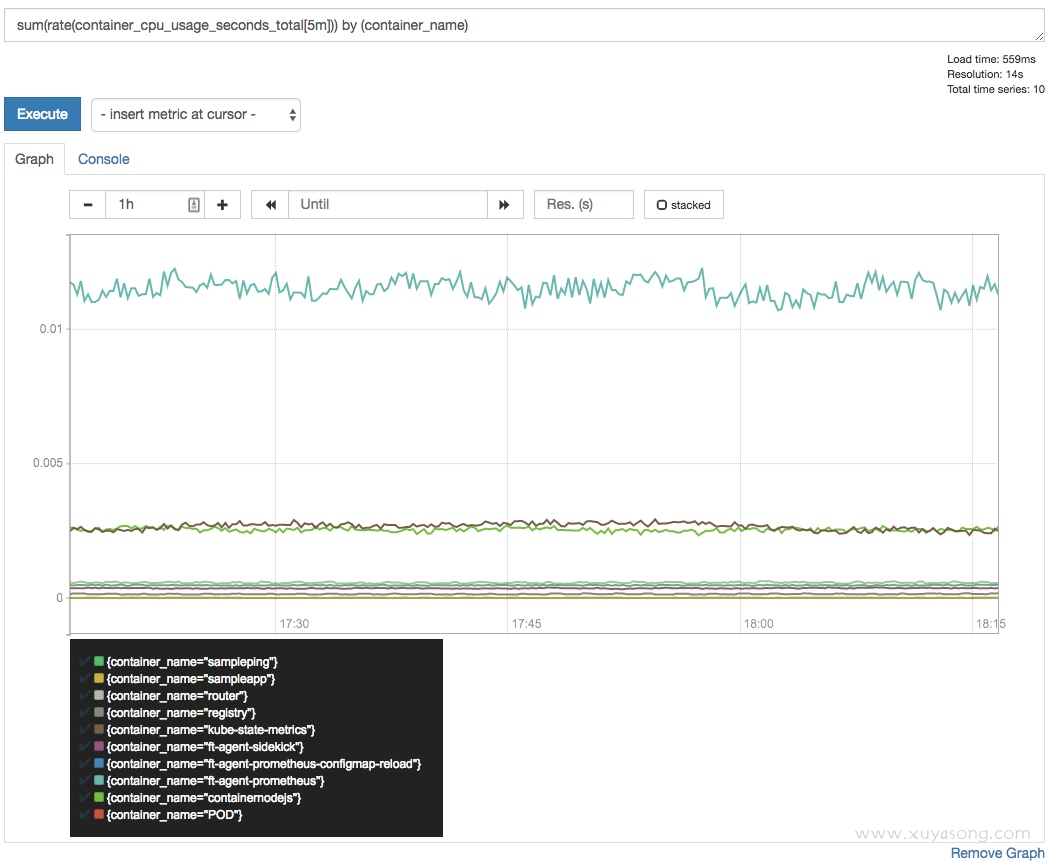
饱和率
如果您定义了CPU的 limit 值,计算饱和度将变得容易得多。
当容器超出其CPU限制时,Linux运行时将“限制”该容器并在container_cpu_cfs_throttled_seconds_total指标中记录其被限制的时间
sum(
rate(container_cpu_cfs_throttled_seconds_total[5m]))
by (container_name)
错误数
就像node_exporter一样,cAdvisor不会暴露CPU错误。
内存
cAdvisor中提供的内存指标是从node_exporter公开的43个内存指标的子集。以下是容器内存指标:
- container_memory_cache-页面缓存的字节数。
- container_memory_rss -RSS的大小(以字节为单位)。
- container_memory_swap-容器交换使用量(以字节为单位)。
- container_memory_usage_bytes-当前内存使用情况(以字节为单位,包括所有内存,无论何时访问。)
- container_memory_max_usage_bytes- 以字节为单位记录的最大内存使用量。
- container_memory_working_set_bytes-当前工作集(以字节为单位)。
- container_memory_failcnt-内存使用次数达到限制。
- container_memory_failures_total-内存 分配失败的累积计数。
利用率
你可能认为使用container_memory_usage_bytes来计算内存使用率,但是这个指标还包括了文件系统缓存,是不准确的。更准确的是container_memory_working_set_bytes,他是 OOM 所关心的指标
sum(container_memory_working_set_bytes {name!〜“ POD”})by name
在上面的查询中,我们需要排除名称包含“ POD”的容器。这是此容器的父级cgroup,将跟踪pod中所有容器的统计信息。
饱和度
和 CPU 的饱和度计算相似,但是和 CPU 不同,无法直接使用指标,因为 OOM 后 container 会被杀掉,可以使用如下查询:
sum(container_memory_working_set_bytes) by (container_name) / sum(label_join(kube_pod_container_resource_limits_memory_bytes,
"container_name", "", "container")) by (container_name)
这里使用label_join组合了 kube-state-metrics 的指标
错误数
kubelet不会暴露内存错误。
磁盘
利用率
在处理磁盘I / O时,我们首先通过查找和读写来跟踪所有磁盘利用率。
cAdvisor有以下指标:
- container_fs_io_time_seconds_total
- container_fs_io_time_weighted_seconds_total
最基本的磁盘I / O利用率是读/写的字节数:
sum(rate(container_fs_writes_bytes_total[5m])) by (container_name,device)
sum(rate(container_fs_reads_bytes_total[5m])) by (container_name,device)
对这些求和,以获得每个容器的总体磁盘I / O利用率。
饱和度
因为没有磁盘的使用限制,无法对容器磁盘饱和度做衡量
错误数
Kubelet没有公开足够的细节,无法查看错误数
网络
利用率
容器的网络利用率,可以选择以字节为单位还是以数据包为单位。网络的指标有些不同,因为所有网络请求都在Pod级别上进行,而不是在容器上进行
下面查询将按pod名称显示每个pod的网络利用率:
sum(rate(container_network_receive_bytes_total[5m])) by (name)
sum(rate(container_network_transmit_bytes_total[5m])) by (name)
饱和度
同样,在不知道最大网络带宽是多少的情况下,网络的饱和度定义不明确。您也许可以使用丢弃的数据包代替,表示当前已经饱和。
- container_network_receive_packets_dropped_total
- container_network_transmit_packets_dropped_total
错误数
cAdvisor提供了
- container_network_receive_errors_total
- container_network_transmit_errors_total
node-exporter 指标分析
node-exporter可以检查节点的核心指标,从利用率,饱和度和错误的角度来看CPU,内存,磁盘和网络的监控指标
由于node_exporter提供了近1000个指标,有时很难知道要关心哪些。您的系统有哪些重要指标?分析的方法有多种多样,我们可以简化和抽象为以下几类:四个黄金信号,USE方法和RED方法。
四个黄金信号
Google在“SRE Handbook”中以“四个黄金信号”的概念为我们提供了一个论述:
- Latency — 延迟
- Traffic — 流量
- Errors — 错误数
- Saturation — 饱和度

当我第一次尝试将四个黄金信号应用于系统中的指标时,我经常被其中的一些术语以及它们如何应用于系统中的各个节点和应用程序所绊倒。
CPU的延迟或流量是多少?Kafka主题的饱和度是多少?
要定义应用程序的饱和度,我们经常需要考虑应用程序使用的基础资源的饱和度。这些资源是什么,我们如何对其进行监控?我们可以使用USE方法
USE 方法
Brendan Gregg在解释系统资源时如何考虑利用率、饱和度、错误方面做得非常出色。
他给出以下定义:
- Resource:所有服务器功能组件(CPU,磁盘,总线等)
- Utilization:资源忙于服务工作的平均时间
- Saturation:需要排队无法提供服务的时间
- Errors:错误事件的计数
他建议(但没有规定)确切地表示在Unix系统的上下文中哪些度量表示利用率,饱和度和错误。本文的其余部分,我将USE方法应用于Kubernetes节点中的资源。
尽管USE方法针对的是资源,具有严格限制的实际物理资源,但是对于在这些资源上运行的软件而言,这是不完整的描述。这就是RED方法的用武之地。
RED 方法
Tom Wilkie解释RED方法为:
- Rate:每秒的请求数。
- Errors:失败的那些请求的数量。
- Duration:这些请求所花费的时间。
从表面上看,RED方法似乎与USE方法和四个黄金信号非常相似。什么时候使用USE vs RED?
USE方法用于资源,RED方法用于服务 — Tom Wilkie
CPU
利用率
现在,我们有两种方法可以帮助您选择要注意的指标。这东西是资源还是应用程序?
集群中的节点具有资源。您的节点在Kubernetes群集中提供的最重要资源是CPU,内存,网络和磁盘。
让我们将USE方法应用于所有这些方法。
node_exporter指标node_cpu会跟踪所有10个CPU mode 在每个内核上花费的所有CPU时间。这些mode是:user, system, nice, idle, iowait, guest, guest_nice, steal, soft_irq and irq。
要计算您的Kubernetes集群中主机的cpu利用率,我们希望对所有mode进行累加, idle, iowait, guest, and guest_nice除外。PromQL看起来像这样:
sum(rate(
node_cpu{mode!=”idle”,
mode!=”iowait”,
mode!~”^(?:guest.*)$”
}[5m])) BY (instance)
关于此查询的一些注意事项:
- 在PromQL中,当同一标签上有多个修饰符时,它们将被AND在一起。
- 所有的node_cpu系列均表示为CPU秒,并且是counter,因此我们需要使用rate()来计算每秒的时间。最终结果显示了每个节点使用的CPU数。
- 最终结果显示了每个节点使用的CPU数。
饱和度
cpu 提供的饱和度,是Unix的平均负载。平均负载是正在运行的进程数加上正在等待运行的进程数。同样,布伦丹·格雷格(Brendan Greg)在Linux平均负载方面有「很长的论述](http://www.brendangregg.com/blog/2017-08-08/linux-load-averages.html)。
node_load1,node_load5和node_load15分别代表1、5和15分钟的平均负载。该指标是一个gauge,已经为您进行了平均。作为一个独立的指标,知道节点有多少个CPU有些用处。
平均负载是10到底好还是坏?这视情况而定。如果将平均负载除以机器拥有的CPU数量,则可以近似得出系统的CPU饱和度。
node_exporter不会直接公开节点CPU的数量,但是如果仅计算上述一种CPU模式(例如“ system”),则可以按节点获取CPU数量:
count(node_cpu{mode="system"}) by (node)
现在,您可以通过以百分比表示的节点上的CPU数量来规范化node_load1指标:
sum(node_load1) by (node) / count(node_cpu{mode="system"}) by (node) * 100
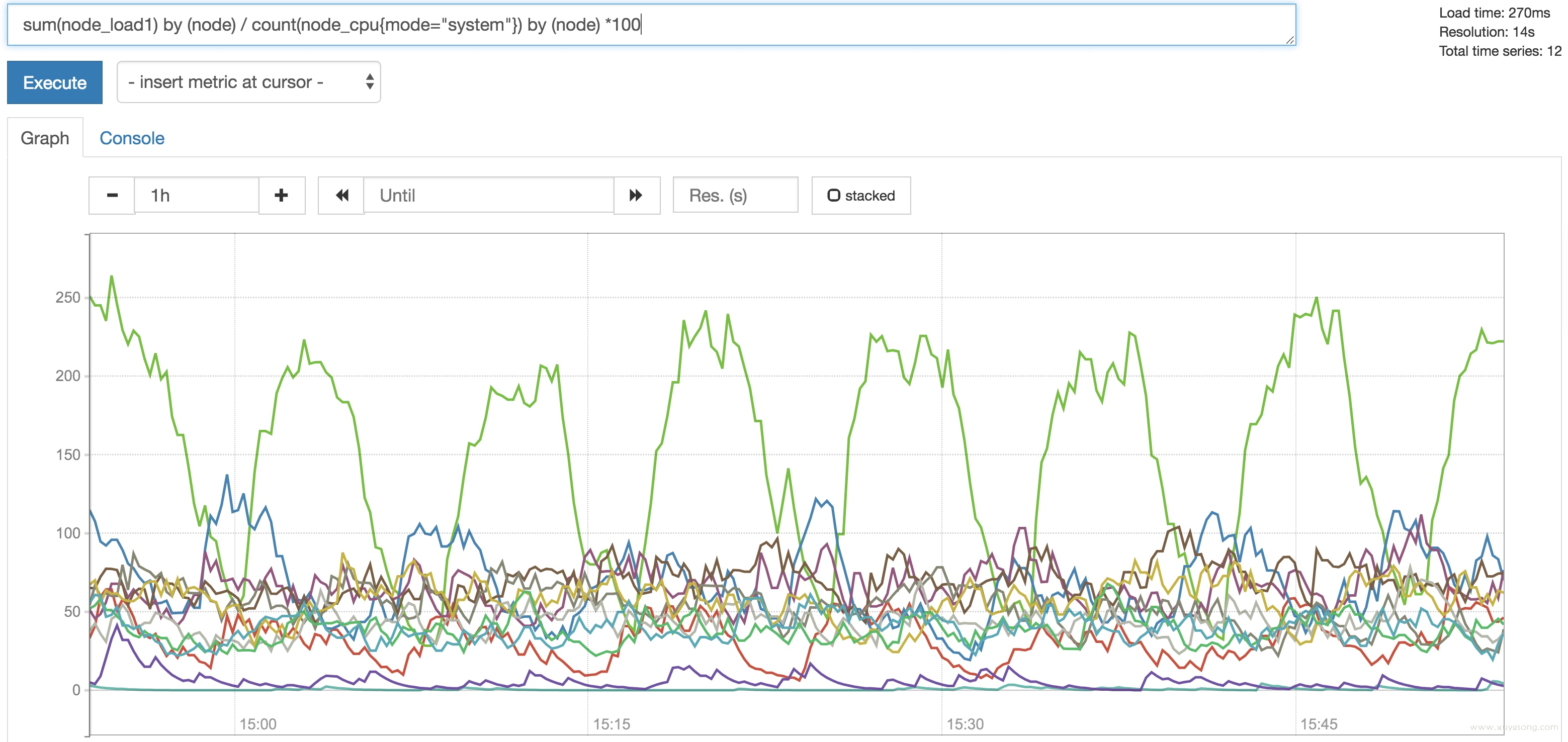
似乎我们的系统之一的CPU饱和度高达250%以上。需要调查一下!
错误数
node_exporter不显示有关CPU错误的任何信息。
内存
由于已知节点上的物理内存量,因此似乎可以更容易地推断出内存利用率和饱和度。可没有那么容易!node_exporter为我们提供了43个node_memory_ *指标供您使用!
Linux系统上的可用内存量不仅仅是报告的“free”内存指标。Unix系统严重依赖于应用程序未使用的内存来共享代码(buffers)和缓存磁盘页面(cached)。因此可用内存的一种度量是:
sum(node_memory_MemFree + node_memory_Cached + node_memory_Buffers)
较新的Linux内核(3.14之后)公开了更好的可用内存指标node_memory_MemAvailable。
使用率
将其除以节点上可用的总内存,即可得到可用内存的百分比,然后从1中减去以得出节点内存利用率的度量:
1 - sum(node_memory_MemAvailable) by (node)
/ sum(node_memory_MemTotal) by (node)
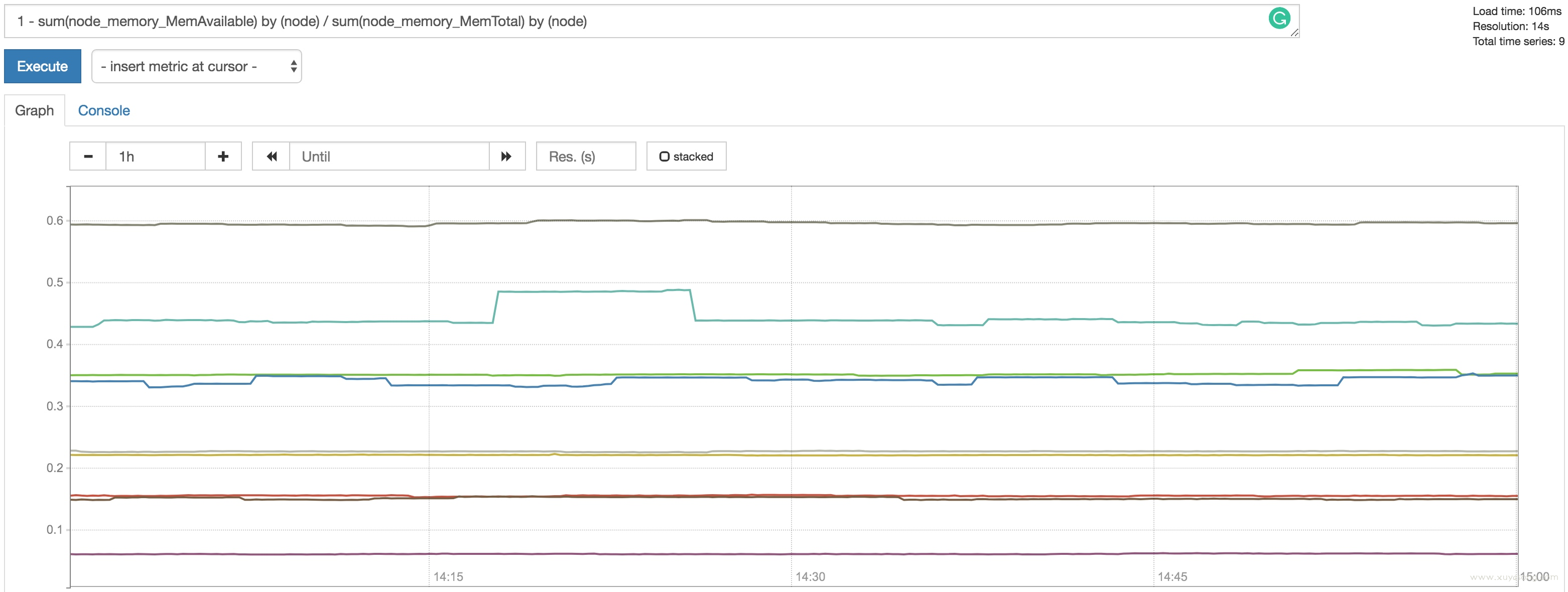
饱和度
内存的饱和度是一个复杂的话题。从理论上讲,Unix系统具有无限数量的“虚拟内存”。如果对内存系统的需求过多,则操作系统将最近未使用的内存page返给硬盘“page to disk”。用某种说法,这称为“going into swap”。在实践中您永远不会想要这个
密切关注节点正在执行的分页数量可以是内存饱和度的一种度量。
node_exporter指标node_vmstat_pgpgin和node_vmstat_pgpgout显示节点的分页活动量。这是一个不完整的指标,因为对于依赖于Linux shared page cache的任何程序使用,内存分页都是正常活动。
Kubernetes为我们提供了一些其他工具来限制集群中使用的内存量。即 limit 限制,容器资源请求和限制(如果实施得当)可以确保您的节点永远不会开始交换。我将在以后的文章中解决这些问题。
错误数
内存错误,在某些硬件上Linux和node_exporter可以通过EDAC,错误检测和纠正报告ECC内存。如果支持,则指标为:
node_edac_correctable_errors_total
node_edac_uncorrectable_errors_total
node_edac_csrow_correctable_errors_total
node_edac_csrow_uncorrectable_errors_total
这些指标在我的机器上无法使用
磁盘
使用率
当我们谈论磁盘利用率和饱和度时,我们需要考虑另外两个方面:磁盘容量和磁盘吞吐量。
- 磁盘容量:磁盘可以存储的数据量
-
磁盘吞吐量:是每秒可以读写磁盘的数量
磁盘容量的饱和度和利用率非常简单;它仅是对所用字节数的一种度量,以可用百分比表示
sum(node_filesystem_free{mountpoint="/"}) by (node, mountpoint) / sum(node_filesystem_size{mountpoint="/"}) by (node, mountpoint)
磁盘吞吐量的利用率和饱和度尚不清楚。
如果使用旋转磁盘,固态硬盘,RAID,网络连接的硬盘或网络块,则需要注意不同的参数。正如我们将在网络中看到的那样,饱和度很难在不知道底层硬件的特性的情况下进行计算,而底层硬件的特性通常对于内核是不可知的。
每个设备的node_exporters会公开一些磁盘写入量之类的指标,还有
- 运行中的IO操作:node_disk_io_now
- IO时间:node_disk_io_time_ms
- 加权的io时间:node_disk_io_weighted。
磁盘吞吐量显然是一个复杂的问题,您选择的指标将取决于硬件以及正在运行的工作负载的类型
饱和度
无
错误数
无
网络
使用率
我们要解决的最后一个资源是网络
根据您的工作量,您可能对发送流量和接收流量比较感兴趣。现在我将利用率定义为已发送和已接收的总和。该查询将按节点为您提供所有网络接口的每秒字节数:
sum(rate(node_network_receive_bytes[5m])) by (node) + sum(rate(node_network_transmit_bytes[5m])) by (node)
饱和度
不知道网络的容量,饱和度将很难确定。我们可以使用丢弃的数据包作为饱和度的侧面论证:
sum(rate(node_network_receive_drop[5m])) by (node) + sum(rate(node_network_transmit_drop[5m])) by (node)
错误数
- node_network_receive_errs: 接受的错误数
- node_network_transmit_errs:发送的错误数
Apiserver 指标分析
概述
kube-apiserver 是集群所有请求的入口,指标的分析可以反应集群的健康状态。
Apiserver 的指标可以分为以下几大类:
- 请求速率和延迟
- 控制器队列的性能
- etcd 的性能
- 进程状态:文件系统、内存、CPU
- golang 程序的状态:GC、进程、线程
基于 RED 方法,评估 apiserver 服务的一些指标:
- Rate 速率:每秒的请求数。
- Error 错误:失败的那些请求的数量。
- Duration 持续时间:这些请求所花费的时间
请求速率和延迟
Rate 速率
sum(rate(apiserver_request_count[5m])) by (resource, subresource, verb)
该查询会列出Kubernetes资源各种操作的五分钟的速率。操作有:WATCH,PUT,POST,PATCH,LIST,GET,DELETE和CONNECT
Error 错误
rate(apiserver_request_count{code=~"^(?:5..)$"}[5m]) / rate(apiserver_request_count[5m])
此查询获取5分钟内错误率与请求率的比率
Duration 请求时间
histogram_quantile(0.9, sum(rate(apiserver_request_latencies_bucket[5m]))
by (le, resource, subresource, verb) ) / 1e+06
查看 90%情况下请求的时间分布
队列情况
所有资源的请求都会被 apiserver 中的 controller 处理,controller 维护了队列,队列的一些指标可以反应资源处理的速度等指标
以apiserver_admission_controller为例:
- apiserver_admission_controller_admission_duration_seconds:准入控制器的处理时间 以秒为单位),通过名称进行标识,并针对每个操作以及API资源和类型(验证或准入)进行细分。
- apiserver_admission_controller_admission_latencies_milliseconds 延迟*
ETCD 的指标
API Server对etcd 的读写有缓存
- etcd_helper_cache_entry_count —缓存中的元素数。
- etcd_helper_cache_hit_count —缓存命中计数。
- etcd_helper_cache_miss_count —缓存未命中计数。
- etcd_request_cache_add_latencies_summary —将条目添加到缓存的时间(以微秒为单位)。
程序指标
apiserver 是 go 程序,目前所有 prometheus 采集的指标都会包含 golang 程序指标,如:
- go_gc_duration_seconds 程序 GC 的耗时
- go_gc_duration_seconds_count 程序 GC 的次数
- go_gc_duration_seconds_quantile 程序 GC 的耗时分布
- go_goroutines goroutines信息
- go_info go环境信息
request
- apiserver_request 请求信息
- apiserver_request_count 请求次数
- apiserver_request_duration_seconds 请求耗时
response
- apiserver_response_sizes 每个组,版本,动作,资源,子资源,范围和组件的响应大小分布(以字节为单位)
- apiserver_response_sizes_bucket 区间分布
- apiserver_response_sizes_count 返回的数量
audit
- apiserver_audit_event: 审计事件
- apiserver_audit_requests_rejected:审核拒绝的请求
参考
访问 apiserver 的 metric 时需要的参数
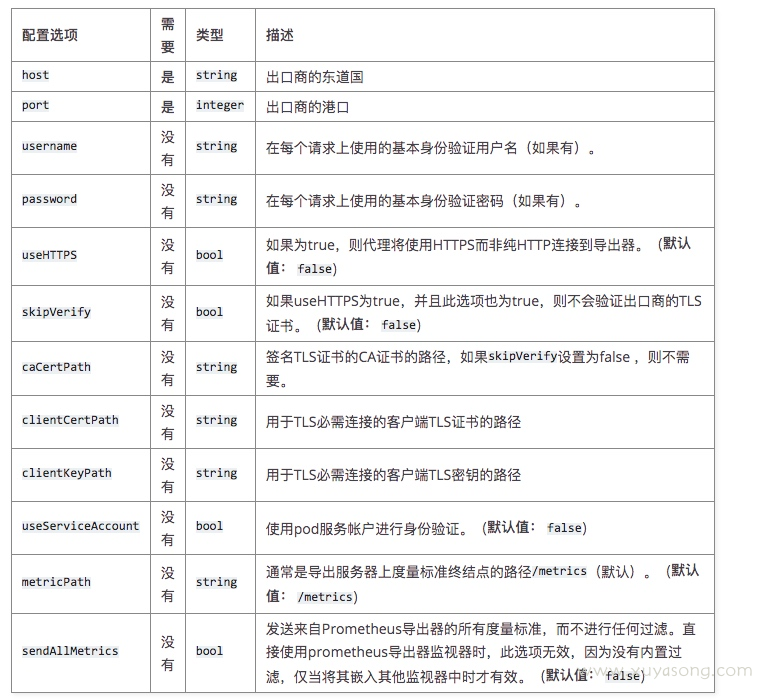
https://docs.signalfx.com/en/latest/integrations/agent/monitors/kubernetes-apiserver.html
https://blog.freshtracks.io/a-deep-dive-into-kubernetes-metrics-part-4-the-kubernetes-api-server-72f1e1210770
ETCD 指标分析
概述
Kubernetes使用etcd来存储集群中组件的所有状态,它是 Kubernetes数据库,监视etcd的性能和行为应该是整个Kubernetes监控计划的一部分,Etcd是用Go语言编写的,并且与Kubernetes的其他服务一样,都是经过精心设计的,并使用Prometheus格式公开其指标。
因为 Etcd 是数据中心,因此访问 metrics 时需要配置鉴权,以防数据外泄。
etcd服务器指标分为几个主要类别:
- Leader的存在和Leader变动率
- 请求已提交/已应用/正在等待/失败
- 磁盘写入性能
- 入站gRPC统计信息
- 集群内gRPC统计信息
Leader 选举
Etcd是一个分布式键值存储。它使用 Rafe协议来选主。Leader可以响应某些事件(例如节点重新启动)而进行更改,重新在Member中选举Leader。更换Leader是很正常的,但是过多的Leader变更也是问题的征兆,可能是网络问题导致的网络分区等
要确认Leader是否选出,etcd_server_has_leader值必须是1,否则就没有leader。这是要配置的告警规则:
# alert if any etcd instance has no leader
ALERT NoLeader
IF etcd_server_has_leader{job="etcd"} == 0
FOR 1m
LABELS {
severity = "critical"
}
ANNOTATIONS {
summary = "etcd member has no leader",
description = "etcd member {{ $labels.instance }} has no leader",
}
Leader变更可以使用 etcd_server_leader_changes_seen_total指标,可以通过以下PromQL查询:
sum(rate(etcd_server_leader_changes_seen_total[5m]))
这个值应该始终为 0,报警规则应该设置为:
# alert if there are lots of leader changes
ALERT HighNumberOfLeaderChanges
IF increase(etcd_server_leader_changes_seen_total{job="etcd"}[1h]) > 3
LABELS {
severity = "warning"
}
ANNOTATIONS {
summary = "a high number of leader changes within the etcd cluster are happening",
description = "etcd instance {{ $labels.instance }} has seen {{ $value }} leader changes within the last hour",
}
请求情况
发送到etcd的写入和配置更改称为投票。Raft 协议确保将其正确提交到集群中。相关 metric 有:
- etcd_server_proposals_committed_total
- etcd_server_proposals_applied_total
- etcd_server_proposals_pending
- etcd_server_proposals_failed_total
失败数目过多应该报警,报警规则应该配置为:
# alert if there are several failed proposals within an hour
ALERT HighNumberOfFailedProposals
IF increase(etcd_server_proposals_failed_total{job="etcd"}[1h]) > 5
LABELS {
severity = "warning"
}
ANNOTATIONS {
summary = "a high number of proposals within the etcd cluster are failing",
description = "etcd instance {{ $labels.instance }} has seen {{ $value }} proposal failures within the last hour",
}
磁盘写入能力
磁盘性能是etcd服务器性能的主要衡量指标,因为在follwer可以确认Leader的提议之前,必须将提案写入磁盘并进行同步。
要注意的两个重要指标是
- etcd_disk_wal_fsync_duration_seconds_bucket
- etcd_disk_backend_commit_duration_seconds_bucket
# etcd disk io latency alerts
# ===========================
# alert if 99th percentile of fsync durations is higher than 500ms
ALERT HighFsyncDurations
IF histogram_quantile(0.99, rate(etcd_disk_wal_fsync_duration_seconds_bucket[5m])) > 0.5
FOR 10m
LABELS {
severity = "warning"
}
ANNOTATIONS {
summary = "high fsync durations",
description = "etcd instance {{ $labels.instance }} fync durations are high",
}
# alert if 99th percentile of commit durations is higher than 250ms
ALERT HighCommitDurations
IF histogram_quantile(0.99, rate(etcd_disk_backend_commit_duration_seconds_bucket[5m])) > 0.25
FOR 10m
LABELS {
severity = "warning"
}
ANNOTATIONS {
summary = "high commit durations",
description = "etcd instance {{ $labels.instance }} commit durations are high",
}
GRPC指标
Etcd使用gRPC在集群中的每个节点之间进行通信。最好跟踪这些请求的性能和错误数。
指标etcd_grpc_total表示按方法分类的grpc调用总数。
etc_grpc_requests_failed_total表示失败次数。
# gRPC request alerts
# ===================
# alert if more than 1% of gRPC method calls have failed within the last 5 minutes
ALERT HighNumberOfFailedGRPCRequests
IF sum by(grpc_method) (rate(etcd_grpc_requests_failed_total{job="etcd"}[5m]))
/ sum by(grpc_method) (rate(etcd_grpc_total{job="etcd"}[5m])) > 0.01
FOR 10m
LABELS {
severity = "warning"
}
ANNOTATIONS {
summary = "a high number of gRPC requests are failing",
description = "{{ $value }}% of requests for {{ $labels.grpc_method }} failed on etcd instance {{ $labels.instance }}",
}
# alert if more than 5% of gRPC method calls have failed within the last 5 minutes
ALERT HighNumberOfFailedGRPCRequests
IF sum by(grpc_method) (rate(etcd_grpc_requests_failed_total{job="etcd"}[5m]))
/ sum by(grpc_method) (rate(etcd_grpc_total{job="etcd"}[5m])) > 0.05
FOR 5m
LABELS {
severity = "critical"
}
ANNOTATIONS {
summary = "a high number of gRPC requests are failing",
description = "{{ $value }}% of requests for {{ $labels.grpc_method }} failed on etcd instance {{ $labels.instance }}",
}
# alert if the 99th percentile of gRPC method calls take more than 150ms
ALERT GRPCRequestsSlow
IF histogram_quantile(0.99, rate(etcd_grpc_unary_requests_duration_seconds_bucket[5m])) > 0.15
FOR 10m
LABELS {
severity = "critical"
}
ANNOTATIONS {
summary = "slow gRPC requests",
description = "on etcd instance {{ $labels.instance }} gRPC requests to {{ $label.grpc_method }} are slow",
}
如何查看 etcd 的读写磁盘的 Latency?
可以通过etcd 的 metrics计算得出:5m 内的磁盘IO 延迟(99%区间)。如大于 500ms 报警
histogram_quantile(0.99, rate(etcd_disk_wal_fsync_duration_seconds_bucket{clusterID=”c-07v3Y2v5”,instanceIP=”100.70.181.251”}[5m])) > 0.5
说点什么
1 评论 在 "容器监控实践—K8S常用指标分析"
[…] 可以使用cadvisor 和 node-exporter的数据进行解释 […]