系统架构图
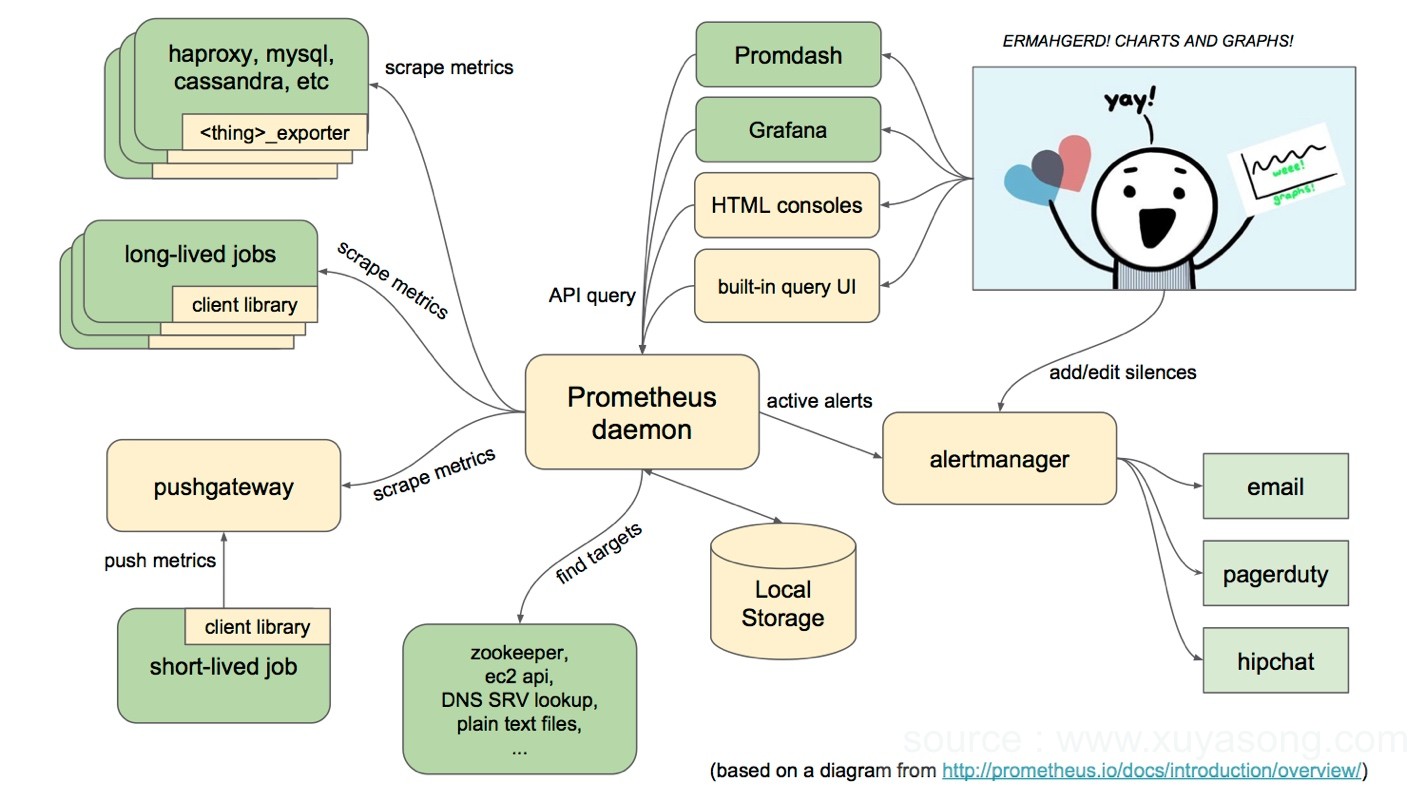
1.x版本的Prometheus的架构图为:
目前Prometheus版本为2.7,架构图为:
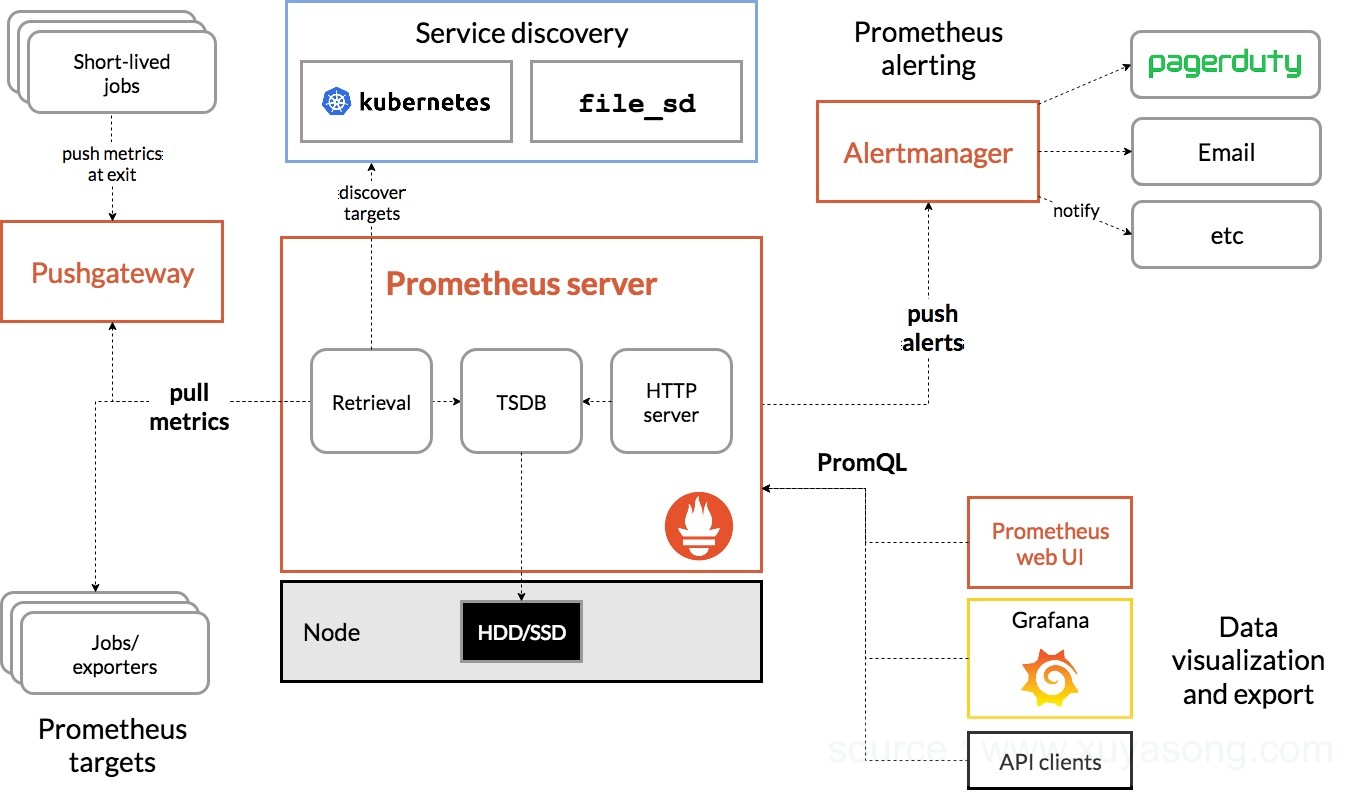
Prometheus从exporter拉取数据,或者间接地通过网关gateway拉取数据(如果在k8s内部署,可以使用服务发现的方式),它默认本地存储抓取的所有数据,并通过一定规则进行清理和整理数据,并把得到的结果存储到新的时间序列中,采集到的数据有两个去向,一个是报警,另一个是可视化。PromQL和其他API可视化地展示收集的数据,并通过Alertmanager提供报警能力。
组件内容
- Prometheus Server
负责从 Exporter 拉取和存储监控数据,并提供一套灵活的查询语言(PromQL)- Retrieval: 采样模块
- TSDB: 存储模块默认本地存储为tsdb
- HTTP Server: 提供http接口查询和面板,默认端口为9090
- Exporters/Jobs
负责收集目标对象(host, container…)的性能数据,并通过 HTTP 接口供 Prometheus Server 获取。支持数据库、硬件、消息中间件、存储系统、http服务器、jmx等。只要符合接口格式,就可以被采集。 - Short-lived jobs
瞬时任务的场景,无法通过pull方式拉取,需要使用push方式,与PushGateway搭配使用 -
PushGateway
可选组件,主要用于短期的 jobs。由于这类 jobs 存在时间较短,可能在 Prometheus 来 pull 之前就消失了。为此,这次 jobs 可以直接向 Prometheus server 端推送它们的 metrics。这种方式主要用于服务层面的 metrics,对于机器层面的 metrices,需要使用 node exporter。 -
客户端sdk
官方提供的客户端类库有go、java、scala、python、ruby,其他还有很多第三方开发的类库,支持nodejs、php、erlang等 -
PromDash
使用rails开发的dashboard,用于可视化指标数据,已废弃 -
Alertmanager
从 Prometheus server 端接收到 alerts 后,会进行去除重复数据,分组,并路由到对收的接受方式,发出报警。常见的接收方式有:电子邮件,pagerduty,OpsGenie, webhook 等。 -
Service Discovery
服务发现,Prometheus支持多种服务发现机制:文件,DNS,Consul,Kubernetes,OpenStack,EC2等等。基于服务发现的过程并不复杂,通过第三方提供的接口,Prometheus查询到需要监控的Target列表,然后轮训这些Target获取监控数据。
其大概的工作流程是:
- Prometheus server 定期从配置好的 jobs 或者 exporters 中拉 metrics,或者接收来自 Pushgateway 发过来的 metrics,或者从其他的 Prometheus server 中拉 metrics。
- Prometheus server 在本地存储收集到的 metrics,并运行已定义好的 alert.rules,记录新的时间序列或者向 Alertmanager 推送警报。
- Alertmanager 根据配置文件,对接收到的警报进行处理,发出告警。
- 在图形界面中,可视化采集数据。
关于Push与Pull
Prometheus采集数据是用的pull也就是拉模型,通过HTTP协议去采集指标,只要应用系统能够提供HTTP接口就可以接入监控系统,相比于私有协议或二进制协议来说开发、简单。优点主要是:
- 开发任何新功能,你甚至可以在电脑上查看你的监控
- 如果目标实例挂掉,你可以很快知道
- 你可以手动指定目标实例,并且在浏览器中查看他的健康状态
总体来说,Pull模式比Push模式更好一些,在监控系统中这也不是一个很重要的点。
如果要使用push的方式,可以使用Pushgateway的方式,如定时任务的采集。
对于定时任务这种短周期的指标采集,如果采用pull模式,可能造成任务结束了,Prometheus还没有来得及采集,这个时候可以使用加一个中转层,客户端推数据到Push Gateway缓存一下,由Prometheus从push gateway pull指标过来。(需要额外搭建Push Gateway,同时需要新增job去从gateway采数据)
推的代表有 ElasticSearch,InfluxDB,OpenTSDB 等,需要你从程序中将指标使用 TCP,UDP 等方式推送至相关监控应用,只是使用 TCP 的话,一旦监控应用挂掉或存在瓶颈,容易对应用本身产生影响,而使用 UDP 的话,虽然不用担心监控应用,但是容易丢数据。
拉的代表,主要代表就是 Prometheus,让我们不用担心监控应用本身的状态。而且,可以利用 DNS-SRV 或者 Consul 等服务发现功能就可以自动添加监控。
当然,InfluxDB 加上 collector,或者 ES 加上 metricbeat 也可以变为 『拉』,而 Prometheus 加上 Push Gateway 也可以变为 『推』。
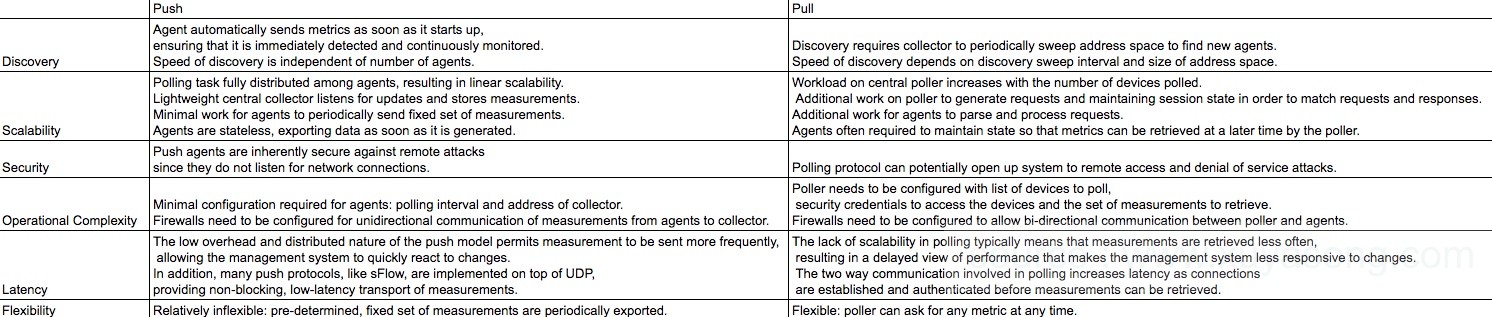
更多区别可以参考下图:
存储机制
Prometheus有着非常高效的时间序列数据存储方法,每个采样数据仅仅占用3.5byte左右空间,上百万条时间序列,30秒间隔,保留60天,大概花了200多G(引用官方PPT)。
Prometheus内部主要分为三大块,Retrieval是负责定时去暴露的目标页面上去抓取采样指标数据,Storage是负责将采样数据写磁盘,PromQL是Prometheus提供的查询语言模块。
Prometheus内置了一个基于本地存储的时间序列数据库。在Prometheus设计上,使用本地存储可以降低Prometheus部署和管理的复杂度同时减少高可用(HA)带来的复杂性。 在默认情况下,用户只需要部署多套Prometheus,采集相同的Targets即可实现基本的HA。同时由于Promethus高效的数据处理能力,单个Prometheus Server基本上能够应对大部分用户监控规模的需求。
同时为了适应数据持久化的问题,Prometheus提供了remote_write和remote_read的特性,支持将数据存储到远端和从远端读取数据。通过将监控与数据分离,Prometheus能够更好地进行弹性扩展。
关于存储用量规划:https://www.jianshu.com/p/93412a925da2
更多:Prometheus存储机制详解
https://yunlzheng.gitbook.io/prometheus-book/part-ii-prometheus-jin-jie/readmd
https://www.cnblogs.com/vovlie/p/7709312.html
https://www.linuxidc.com/Linux/2018-04/152057.htm
https://segmentfault.com/a/1190000008629939
https://www.infoq.cn/article/Prometheus-theory-source-code
关于日志处理
不建议将日志监控放在Prometheus中,这不是他的专长,还是使用ELK或EFK的方式处理日志信息
竞品对比
参考: https://toutiao.io/posts/fsjq8t/preview
未来规划
- 服务端度量指标元数据支持
在度量指标类型和其他元数据仅仅在客户库和展示格式中使用,并不会在Prometheus服务中持久保留或者利用。将来我们计划充分利用这些元数据。第一步是在Prometheus服务的内存中聚合这些数据,并开放一些实验性的API来提供服务 -
支持OpenMetrics
OpenMetrics组开放了一个新的监控指标暴露标准,我们将支持这种标准:https://openmetrics.io/ -
回溯时间序列
允许将过去一段时间的数据发送到其他的监控系统 -
HTTP服务支持TLS安全认证
当前的Prometheus, Alertmanager和一些官方exporter,暴露服务时,都不支持tls认证,有很大的安全风险,现在的实现都是基于反向代理,之后将内置到组件中
- 支持子查询
当前的Promq不支持子查询,如max_over_time() of a rate()),后续将会支持
- 支持生态建设
Prometheus有很多的client库和exporter,我们将会对其进行规范和生态建设。
在K8S中使用
在之前的版本中,k8s默认以及推荐的监控体系是它自己的一套东西:Heapster + cAdvisor + Influxdb + Grafana,1.8后Heaspter由Metric-server替代。如果你部署了Dashboard,就能看到监控数据(来自heapster)
k8s 自身的 HPA (Horizontal Pod Autoscaler),默认从 Heapster 中获取数据进行自动伸缩
1.8版本以后,K8S希望将核心监控指标收拢到metric api的形式,而自定义监控指标,由prometheus来实现,prometheus正式成为k8s推荐的监控实现方案。
参考文档:
- https://www.ibm.com/developerworks/cn/cloud/library/cl-lo-prometheus-getting-started-and-practice/index.html
- https://prometheus.io/docs/introduction/faq/#why-do-you-pull-rather-than-push
- https://www.kancloud.cn/cdh0805010118/prometheus/719344
- https://yunlzheng.gitbook.io/prometheus-book/part-ii-prometheus-jin-jie/readmd
本文为容器监控实践系列文章,完整内容见:container-monitor-book
说点什么
欢迎讨论